Codierungssysteme mit Audiodatenreduktion
0 Einleitung ^
In den letzten Jahren wurde die
analoge im wesentlichen durch die digitale Audiotechnik ersetzt.
Gleichzeitig entstanden neue Anwendungen fuer Netz, Radio- und
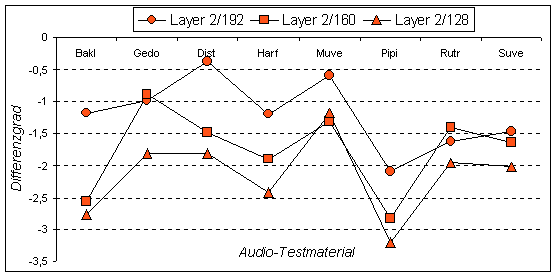
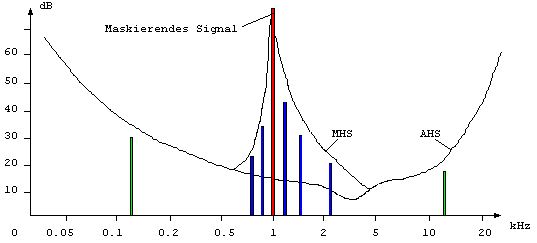
Multimediasysteme, welche sich mit einigen Beschraenkungen konfrontiert
sahen, beispielsweise bei der Kanalbandbreite, der Speicherkapazitaet und
den Kosten. Diese neuen Anwendungen verlangen nach digitaler Audioausgabe
in CD-Qualitaet bei moeglichst geringen Bitraten. Seit einiger Zeit werden
daher verstaerkte Forschungen zur Entwicklung entsprechender
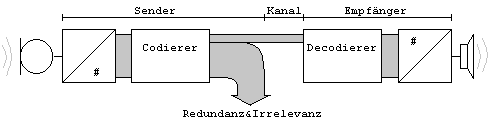
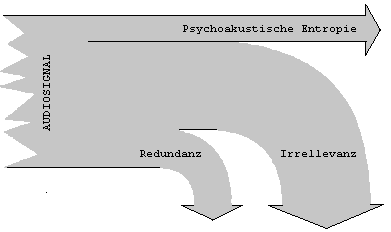
Codierungsalgorithmen unternommen. Das Ziel ist eine kompakte digitale Wiedergabe der Audiosignale, zwecks effizienter uebertragung und Speicherung. Mit anderen Worten, ein Signal soll mit geringstem Datenaufwand versendet und bei einem Empfaenger rekonstruiert werden koennen. Das Datenmaterial laesst sich reduzieren, indem irrelevante und redundante Anteile aus ihm entfernt werden. Dieses einfache Grundprinzip wird durch folgende Abbildung veranschaulicht.
Die Entwicklung leistungsfaehiger
Algorithmen, welche hoechstmoegliche Qualitaet bei geringstem
Datenaufwand liefern sollen, ist bis heute nicht abgeschlossen.
Immer wieder entstehen neue Ideen zur noch effizienteren
Verarbeitung der Audiosignale. Viele Algorithmen wurden bereits
vorgeschlagen, einige von ihnen wurden zu internationalen und/oder
kommerziellen Standards. Da die einzelnen Codierungsverfahren in der Regel aufeinander aufbauen, ist es notwendig, sich ebenfalls mit frueheren Entwicklungen zu beschaeftigen, um die Funktionalitaet aktueller Verfahren verstehen zu koennen. Ein sehr aktuelles Verfahren, welches derzeit breite Anwendung findet, ist der MPEG-Standard ISO/IEC-11172-3 Layer 3, auch kurz MP3 genannt. Dieses Format wird vorrangig genutzt, um Musik im Internet bereitzustellen und zu uebertragen. Obwohl dieses Thema auf breites oeffentliches Interesse stoesst, wird in der Anwenderliteratur oft nur sehr oberflaechlich darauf eingegangen. Ausserdem mangelt es besonders an deutschsprachiger Fachliteratur auf diesem Gebiet. Diese Diplomarbeit soll einen Beitrag zur Verstaendnisfoerderung leisten. Der Schwerpunkt wird dabei auf dem genannten Codierungsverfahren MPEG-11172-3 Layer 3 liegen, aber auch andere Methoden zur Codierung von Audiosignalen sollen erlaeutert werden. Die Arbeit ist folgendermassen aufgebaut. Zunaechst werden verschiedene Arten von Codierungalgorithmen in ihrer Struktur und Verfahrensweise beschrieben und anschliessend in ihrer Qualitaet bewertet. Alle beschriebenen Algorithmen sind verlustbehaftete Kompressionsschemen, welche versuchen, psychoakustische Prinzipien auszunutzen und somit geringe Bitraten auf dem uebertragungskanal zu erhalten. Am Ende dieses Abschnitts folgt die Aufstellung der Aufgabe zur Diplomarbeit. Der Hauptteil (Abschnitte 2 und 3) beschaeftigt sich dann tiefgreifend mit dem Standard MPEG-11172-3 Layer 3 und geht dabei auch auf Grundlagen zur Psychoakustik ein. Der praktische Teil (Abschnitt 3) dieser Arbeit ist die Entwicklung eines Demonstrationsmodells fuer die MP3-Codierung. Dabei sollen die einzelnen Etappen der Signalverarbeitung grafisch dargestellt werden und ueber ein Benutzermenue abzufragen sein. Das Programm wird anschliessend dokumentiert und getestet. Letztendlich folgt die abschliessende Zusammenfassung der Diplomarbeit. Da sich viele angesprochene Entwicklungen auch mit der Codierung anderer Quellmaterialen (z.B. Grafik) beschaeftigen, waere noch anzumerken, dass bei saemtlichen Codierungsverfahren jeweils nur der Anteil zur Audiocodierung gemeint ist. 1 Audio-Codierungs-Algorithmen ^
Vor der
Betrachtung verschiedener Klassen von Codierungsalgorithmen ist es
sinnvoll, die haeufigen charakteristischen uebereinstimmungen der
Verfahren festzuhalten. Die verschiedenen Kompressionssysteme
erzielen ihren Codierungsgewinn
durch die Ausnutzung psychoakustischer Irrelevanz und statistischer
Redundanz. Die Algorithmen basieren auf einer Grundstruktur, welche in
folgender Abbildung gezeigt wird.
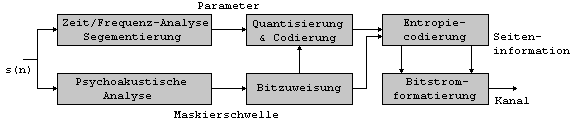
Dabei wird folgendermassen
vorgegangen. Zu allererst wird das Eingangssignal in Rahmen
variierender Laenge (2-50ms) eingeteilt, welche dann durch eine
Zeit/Frequenz-analyse aufgeloest werden. Diese Analyse naehert sich
den zeitlichen und spektralen Merkmalen des menschlichen Gehoers an.
Sie wandelt das Eingangssignal in einen Satz von Parametern, welche
dann entsprechend psychoakustischer Regeln quantisiert und codiert
wird.
Abhaengig von Zielsetzung und Designphilosophie kann die Zeit/Frequenz-Analyse verschiedene Verfahren beinhalten, wie beispielsweise einheitliche Umformung, Bandpassfilterung oder hybride Transformation. Das Mass der Klangverzerrung wird durch die psychoakustische Signalanalyse gesteuert, welche das Potential der moeglichen Signalmaskierung (Verdeckung) einschaetzt. Auf diesen Punkt wird im Hauptteil noch naeher eingegangen. Jedenfalls uebergibt das psychoakustische Modell eine Maskierungsschwelle, bis zu der ein Signal an verschiedenen Punkten veraendert werden darf, ohne dass spaeter beim rekonstruierten Signal hoerbare Artefakte auftreten. Der Quantisierungs- und Codierungsabschnitt nutzt statistische Effekte aus, um die Datenmenge zu reduzieren. Er bedient sich dabei klassischer Techniken, wie der Puls-Code-Modulation (PCM), bzw der angepassten PCM (APCM). Ist der kompakte Parametersatz geformt, werden die verbleibenden redundanten ueberreste durch Entropiecodierung (z.B. Huffman- und Lauflaengencodierung) weitest moeglich entfernt. Die Parameter werden dann mit einer fuer die Decodierung benoetigten Seiteninformation versehen und an den Empfaenger uebertragen. 1.1 Klassifizierung der Codierungsverfahren fuer Tonsignale ^ Die in Tab.1 enthaltenen Algorithmen werden nun der Reihe nach beschrieben: 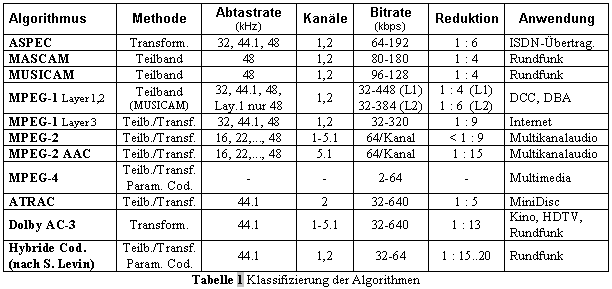
1.2 Transformationscodierer ^
Algorithmen zur Transformationscodierung erreichen
hochaufloesende Spektralschaetzungen auf Kosten der zeitlichen
Aufloesung. Viele solcher Algorithmen wurden vorgeschlagen. Da
waeren zu nennen OCF (Optimum Coding in the Frequency Domain) von
Brandenburg, PXFM (Perceptual Transform Coder) von Johnston, der von
Brandenburg und Johnston gemeinsam entwickelte
AT&T-Hybridcodierer und der CNET-Codierer von Mahieux und Petit
(1).
Schroeder, Brandenburg, Johnston, Herre und Mahieux entwarfen dann 1991 gemeinsam einen flexiblen Codieralgoritmus namens ASPEC (Adaptive Sprectral Entropy Coding of High Quality Music Signals), der die besten Merkmale der vorangegangen Entwicklungen zusammenfasst und sich erfolgreich um die Einbeziehung in die MPEG-Standards bewarb. 1.2.1 ASPEC
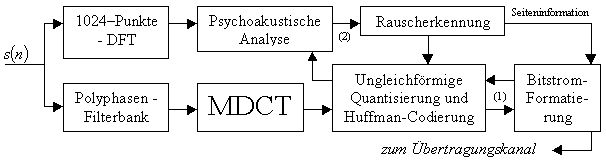
ASPEC kombiniert also Elemente
aller seiner Vorgaenger. Fuer die psychoakustische Analyse teilt der
Algorithmus zunaechst das Eingangssignal in Segmente von 1024 Abtastungen
ein. Wie bei OCF und CNET wird die MDCT (Modifizierte Diskrete
Cosinustransformation) zur Zeit/Frequenz-Analyse genutzt, welche das in
der Filterbank zerlegte Signal in den Frequenzbereich transformiert. MDCT
bietet den Vorteil ueberlappender Zeitfenster bei Erhaltung kritischer
Abtastungen. Die Entwicklung schneller DFT-basierter Algorithmen machte
die MDCT ausfuehrbar fuer Echtzeit-Anwendungen.
Das Maskierungsmodell innerhalb
der psychoakustischen Analyse, welches mit einer PE-Messung
(Perceptual Entropy) die wahrnehmbare relevante Information des
Signals und somit die Maskierungsschwelle gerade noch wahrnehmbarer
Verzerrung (JND - just noticable distortion) bestimmt, gleicht dem
in PXFM und AT&T-hybrid verwendeten Modell. Es beinhaltet
ausserdem ein verfeinertes Schema zur Tonalitaetsschaetzung bei
geringen Bitraten.
Die Quantisierungs- und Codierungsprozeduren nutzen ein in OCF vorgeschlagenes Schleifenpaar, sowie auch ein in CNET entwickeltes Blockcodierschema. In einer inneren Schleife {1} wird unter iterativer Erhoehung der Quantisierungsschrittgroesse bei jeder Aktualisierung ein neuer Bitstrom formatiert, bis die gewuenschte Bitrate erreicht ist. Die aeussere Schleife {2} durchlaeuft unter anderem die Maskierungsfunktion, bis die JND-Kriterien erfuellt sind oder ein maximaler Durchlaufwert erreicht wurde. Durch geeignete Spektraldescriptoren werden die Transformationskoeffizienten normiert, quantisiert und codiert. Anhaeufungen maskierter Koeffizienten werden ausserdem Lauflaengen- und Huffmancodiert. Zeitliche Artefakte (Pre-Echos) werden durch einen von Schroeder entwickelten Fensterschaltmechanismus gesteuert. Im Bitstromformatierer werden die codierten Transformationskoeffizienten dann fuer die serielle uebertragung vorbereitet. ASPEC bietet verschiedene Qualitaetslevel, von 64 bis 192kbps pro Kanal. Die Abtastrate laesst sich zwischen 32, 44.1 und 48kHz umschalten. ASPEC formte die Grundlage fuer MPEG-1 Layer 3 und MPEG-2-Standards. Aufgrund seiner Echtzeitfaehigkeit kann das System beispielsweise als Ersatz einer Tonmietleitung verwendet werden, wodurch sich wegen der geringen Kosten einer ISDN-Waehlverbindung bereits nach wenigen Einsaetzen ein sehr guenstiges Kosten/Nutzen-Verhaelnis ergibt. 1.3 Teilbandcodierer ^
Wie die Transformationscodierer, so nutzen auch die Teilbandcodierer
Signalredundanz und psychoakustische Irrelevanz aus. Anstelle
einzelner Transformationen nutzen diese Codierer jedoch eine
Frequenzbereichsdarstellung des Signals. Das hoerbare
Frequenzspektrum (20Hz - 20kHz) wird durch eine Bank von
Bandpassfiltern in Frequenzteilbaender aufgegliedert.
Die Ausgabe eines jeden Filters wird dann abgetastet und codiert. Beim Empfaenger gehen die Signale durch einen Demultiplexer, werden decodiert, demoduliert und zum rekonstruierten Signal zusammengesetzt. Teilbandcodierer realisieren ihr Codierungsziel durch effiziente Quantisierung und Codierung der dezimierten Filterbankausgaben. Dieser Abschnitt beschaeftig sich speziell mit den individuellen Algorithmen des Instituts fuer Rundfunktechnik (IRT) und den Philips Research Laboratories. Die Algorithmen flossen schliesslich zusammen in MUSICAM (Masking Pattern Universal Subband Integrated Coding and Multiplexing), welcher spaeter in die MPEG-Standards einbezogen wurde (2). 1.3.1 MASCAM
Theile, Stoll und Link
entwickelten bei IRT diesen Teilbandcodierer, welcher auf einer
QMF-Filterbank (quadrature mirror filter) basiert. MASCAM steht fuer
Masking Pattern Adapted Subband Coding. Der Codierer arbeitet mit 24
ungleichen Teilbaendern, mit den Bandbreiten 125Hz fuer Signale bis
1kHz, 250Hz bis 2kHz, 500Hz bis 4kHz, 1kHz bis 8kHz und 2kHz bis
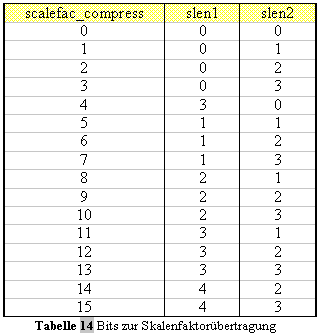
16kHz. Die Teilband-Ausgabesequenzen erfolgen in 2ms-Bloecken. Fuer
jeden Block eines jeden Teilbandes wird ein Skalenfaktor zur
Normierung quantisiert und uebertragen.
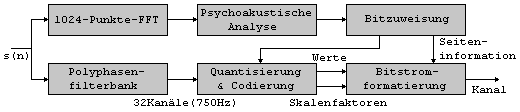
Die Bitzuweisung leitet sich aus einer vereinfachten psychoakustischen Analyse her. Der MASCAM-Codierer erreicht hochqualitative Resultate fuer Eingangssignale mit 15kHz Bandbreite, bei Bitraten zwischen 80 und 100kbps pro Kanal. Ein gleichartiger Codierer wurde waehrend dieser Zeit bei Philips entwickelt. Dabei wurden zwei Teilbandschemen untersucht, basierend auf einer 20- und einer 26-Band-Filterbank. Wie schon das originale MASCAM-System baut auch der Philips-Coder auf ein stark vereinfachtes Maskierungsmodell. Die Schwellen werden aus einer modellhaften Basilar-Erregungsfunktion hergeleitet. Die durch das Maskierungsmodell vorgegebenen SNR-Ziele (Signal-to-Noise-Ratio) werden auf eine diskrete APCM angewendet, um die Ausgabe eines jeden Teilbandes zu normieren. Der Philips-Codierer liefert Codierung in CD-Qualitaet bei 110 und 180kbps, jeweils fuer die 20- und 26-Bandversion. 1.3.2 MUSICAM
Dieses Verfahren entwickelte sich
hauptsaechlich aus den MASCAM-Verfahren von IRT (Deutschland) und
Philips (Niederlande). Dabei wird das breitbandige Eingangssignal
zunaechst in 32 Teilbaender mit jeweils 750Hz Breite zerlegt, woraus
sich eine Frequenzbandbreite von 24kHz fuer das Audiosignal ergibt.
Aus den Teilbaendern werden die in 8ms-Abschnitten auftretenden Maxima bestimmt und daraus jeweils ein Skalenfaktor gebildet. Da sich Skalenfaktoren relativ selten aendern, bietet sich dafuer eine Codierung an, die lediglich \'c4nderungen uebertraegt und/oder Entropiecodierung. Parallel dazu wird mit Hilfe der psychoakustischen Analyse die erforderliche Aufloesung in jedem Teilband bestimmt, damit das verbleibende Rauschen mit Sicherheit maskiert wird. Wichtig fuer die Codierung ist hier besonders die durch die FFT bestimmte Feinstruktur des Frequenzganges. Wegen der gewaehlten Filterung (Polyphasenfilter) ergeben sich konstante Bandbreiten (750Hz). Ohrgemaess sind jedoch relativ konstante Bandbreiten kritisch, da sie im unteren Frequenzbereich Halboktaven bis Oktaven entsprechen. 750Hz sind hier also zu breit. Alle diese Informationen fuehren zu einer zeitlich schwankenden Bitzuweisung fuer die einzelnen Teilbaender. Skalenfaktoren und Bitzuweisung steuern die Datenreduktion. Die codierten Informationen werden dann mit Skalenfaktoren und Seiteninformation zu einem Multiplexsignal zusammengefasst. Die Decodierung erfolgt invers zur Codierung. Die fuer den Prozess notwendige "Intelligenz" wird in der Seiteninformation mitgeliefert. Daher ist der Decodierer wesentlich einfacher aufgebaut. MUSICAM erreicht 128 bzw. 96kbps pro Kanal und wurde von der ISO/IEC fuer MPEG-1 Layer1+2 ausgewaehlt, infolge seiner attraktiven Kombination aus hoher Qualitaet, annehmbarer Komplexitaet und ertraeglicher Verzoegerung (20). 1.4 Standards ^
Dieser Abschnitt gibt eine Beschreibung einiger internationaler
und kommerzieller Standards zur Audiocodierung. Der Schwerpunkt
liegt dabei auf den MPEG-Standards, aber auch auf ATRAC und
Dolby-AC-3 wird eingegangen.
1.4.1 MPEG-Standards
Seit 1988 unternimmt die ISO/IEC
JTC1/SC29 WG11, genannt MPEG (Moving Pictures Expert Group),
Standardisierungen von Kompressionstechniken fuer Video und Audio. Die
Standards dieser Gruppe sind die ersten internationalen Standards auf dem
Gebiet der digitalen Audiokompression und flossen bereits in viele
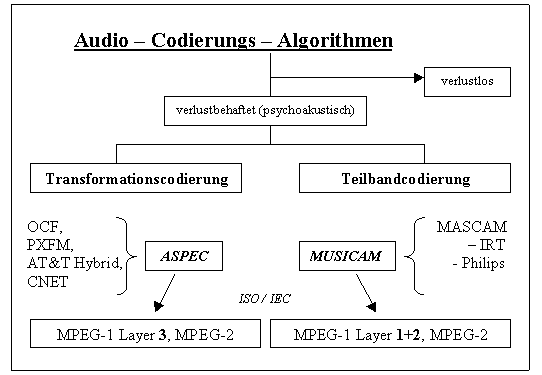
Anwendungen ein. Die folgende Abbildung (Eigenkreation) gibt noch einmal
eine kurze Zusammenfassung zur Entwicklung der Standards MPEG-1 und
MPEG-2, deren Beschreibung nun folgt.
 1.4.1.1 MPEG-1 ISO/IEC 11172-3, Layer 1 und 2
Waehrend Layer 1 noch eine
vereinfachte Form des MUSICAM-Verfahrens darstellt, ist Layer 2 fast
identisch, abgesehen von einem speziellen HEADer, der ein Synchronwort und
weitere wichtige Informationen zum Signal beinhaltet. Neben der
Abtastfrequenz von 48kHz (Layer 1) sind bei Layer 2 auch 44.1 und 32kHz
moeglich. Der Codierungsalgorithmus arbeitet folgendermassen. Das
Eingangssignal s(n) wird zunaechst durch eine Polyphasenfilterbank in 32
Baender eingeteilt.
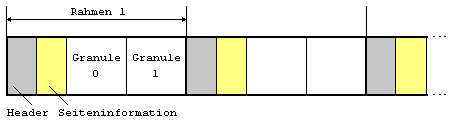
Fuer jedes Teilband werden 36 Abtastwerte generiert, welche wiederum in Bloecke von jeweils 12 Abtastungen (Granulen) eingeteilt werden. Aus jedem Block wird die maximale Amplitude bestimmt und spaeter als Skalenfaktor mit 6bit codiert. Bei Signalen mit sehr geringen Abweichungen zwischen den Skalenfaktoren eines Teilbandes kann dieses Teilband mit nur einem Skalenfaktor codiert werden, andernfalls eben mit zwei oder drei.
Fuer die psychoakustische Analyse
und Festlegung der JND-Schwelle wird eine 512-Punkt- (Layer 1) oder
1024-Punkt- (Layer 2) FFT berechnet. Beide Layer verwenden das
Psychoakustische Modell 1. Die dezimierten Teilbandsequenzen und die
Skalenfaktoren werden quantisiert und zusammen mit der
Seiteninformation (SI) sowie einem Fehlerschutz-code an den
Empfaenger uebertragen.
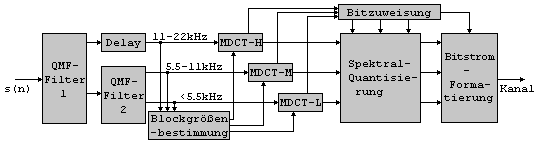
1.4.1.2 MPEG-1 ISO/IEC 11172-3, Layer 3
Layer 3 erreicht
Leistungsverbesserungen durch verschiedene zusaetzliche Mechanismen,
welche auf das Layer-1/2-Fundament aufgesetzt wurden. Eine
Hybridfilterbank zur besseren Frequenzaufloesung fuehrt zu einer
besseren Anpassung an das Verhalten kritischer Baender. Die
angepasste Segmentierung beispielsweise wird zur besseren
Pre-Echo-Steuerung genutzt.
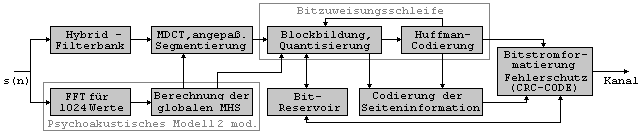
Die verfeinerte Bitzuweisung und Quantisierungsstrategie, welche auf ungleichfoermiger Quantisierung, Analyse durch Synthese und Entropiecodierung beruhen, ermoeglichen eine reduzierte Bitrate und verbesserte Qualitaet. Es handelt sich dabei um eine Schleifen-prozedur, bei der eine innere Schleife die ungleichmaessigen Quantisierungsschrittgroessen fuer jeden Block anpasst, bis die gewuenschte Bitrate der Transformationskomponenten erreicht ist. Spaetestens hier faellt der unmittelbare Zusammenhang zu ASPEC auf. Die aeussere Schleife bewertet die Tonalitaet des codierten Signals (Analye durch Synthese), relativ zur JND-Schwelle. Ausserdem wird ein verbessertes psychokustisches Modell verwendet. Da es sich bei diesem Codierungsalgorithmus um das Hauptthema der Diplomarbeit handelt, soll dieser kurze Einblick an dieser Stelle ausreichen. Eine ausfuehrliche Beschreibung folgt unter Punkt 2.2 (6). 1.4.1.3 MPEG-2 ISO/IEC 13818-3
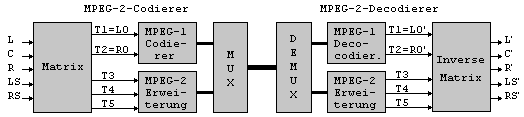
Die zweite Phase von MPEG
beinhaltet zwei Multikanal-Standards. Einer davon (dieser) ist
abwaertskompatibel zu MPEG-1. Mit Rueckkompatibilitaet ist es moeglich,
Multikanal-Audio jederzeit per Zweikanal-Stereo-Decoder wiederzugeben. Ein
wichtiges Beispiel waere das Europaeische DAB-System (Digital Audio
Broadcast), welches in der ersten Generation MPEG-1-Stereo-Decodierer
nutzt, spaeter jedoch Multikanal-Audio bieten wird.
Abwaertskompatibilitaet beinhaltet
die Nutzung von Kompatibilitaetsmatrizen. Ein Downmix von fuenf Kanaelen
(Matrixing) liefert ein korrektes Stereosignal, bestehend aus linken (L0)
und rechten Kanal (R0). L0 und R0 werden als MPEG-1-Format ueber die
Kanaele T1 und T2 uebertragen, die Kanaele T3, T4 und T5 formen zusammen
das erweiterte Multikanalsignal. Der typische Gleichungssatz ist (3):
Weitere Alternativen sind
moeglich, einschliesslich L0=L und R0=R, die Faktoren a, b und d
schwaechen das Signal, um einen Overload waehrend der Berechnung des
kompatiblen Stereosignals (L0,R0) zu vermeiden. T3, T4 und T5
muessen so gewaehlt werden, dass der Decodierer das komplette
Multikanal-Signal rekonstruieren kann. Das erweiterte Signal wird
immer im MPEG-1-Bitstrom (L0 & R0) mitgeliefert, was die
moegliche erreichbare Kompressionsrate reduziert.
Abwaertskompatibilitaet wird erreicht durch die UEbertragung der Kanaele L0 und R0 im Abschnitt der Teilbandabtastung des MPEG-1-Audiorahmens und aller erweiterten Multikanalsignale (T3, T4 und T5) im ersten Teil des Rahmens, welcher fuer zusaetzliche Daten reserviert ist. Diese zusaetzlichen Daten werden im MPEG-1-Decodierer ignoriert. Die Laenge dieses zusaetzlichen Datenfeldes ist im Standard nicht festgelegt. Im Decodierer vom Typ MPEG-2 wird das komplette Multikanal-Signal rekonstruiert, mit seinen Komponenten L, R, C, LS und RS. Dies erfolgt durch ein "Dematrixing" von L0, R0, T3, T4 und T5. Matrixing ist also offenbar erforderlich, um Abwaertskompatibilitaet zu erzielen. Jedoch im Zusammenhang mit psychoakustischer Codierung kann aufgrund dessen unmaskiertes Quantisierungsrauschen auftreten. In gewissen Situationen (beim Dematrixing) kann eine maskierte Summen- und Differenzkomponente in einem speziellen Kanal verschwinden. Da diese zur Maskierung des Quantisierungsrauschens im Kanal gebraucht wird, kann dieses Rauschen eventuell hoerbar werden. Der in MPEG-2 optional vorhandenen variable Bitratenmodus kann herangezogen werden, um schwierige Audioinhalte mit einer momentan hoeheren Bitrate zu codieren. MPEG-1-Decodierer haben eine Bitraten-beschraenkung (384kbps in Layer 2). Um diese Beschraenkung zu ueberwinden, wird der erweiterte Teil eines kompatiblen Multikanalsignals mit hoeheren Raten uebertragen (3). 1.4.1.4 MPEG-2 ISO/IEC AAC 13818-7 - Audio Advanced Coding
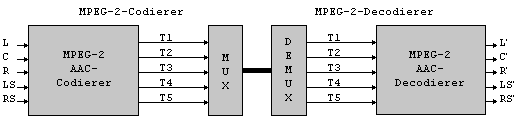
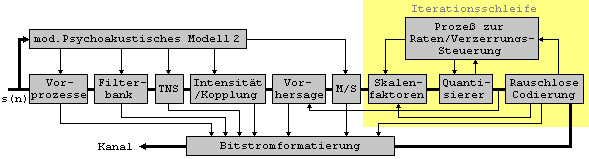
Der zweite Standard innerhalb von
MPEG-2 unterstuetzt Anwendungen, welche keine Kompatibilitaet mit dem
MPEG-1-Stereoformat benoetigen. Der MPEG-2 AAC-Standard verwendet
hochaufloesende Filterbaenke, Vorhersagetechniken und rauschlose
Codierung, welche auf juengsten Gutachten und Modul-Definitionen basieren.
Die Module beinhalten optionale Vorprozesse, eine Filterbank, ein
psychoakustisches Modell, zeitliche Rauschformung, Multikanalcodierung,
rauschlose Codierung und Bitstromformatierung.
Zu den optionalen Prozessen gehoeren die Mitte/Seite-Entscheidung (M/S), die Vorhersage, welche das bereits quantisierte Spektrum des vorangegangen Rahmens kennt, die Stereo-Intensitaets-Steuerung bzw. Kanal-Kopplungs-Steuerung, die zeitliche Rauschformung (TNS - time noise shaping) und die Vorprozesse fuer zusaetzlichen Codierungsgewinn. Die Filterbank beinhaltet eine 1024-Punkt-MDCT. Das psychoakustsiche Modell wurde von MPEG-1 uebernommen (Modell 2). Das Modul zur zeitlichen Rauschformung steuert die zeitliche Abhaengigkeit des Quantisierungsrauschens (14).
Zu den Phasenwerten gelangt man
durch folgende Berechnung:
Die Differenzierung
gibt einen Frequenzoffset, welcher
zu
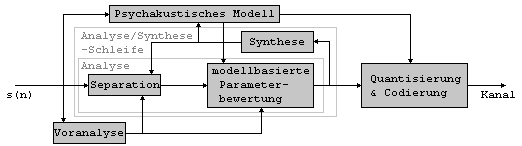
2 Der Standard ISO/IEC 11172-3 Layer 3- ^ 2.1 Besonderheiten der psychoakustischen Modelle-^
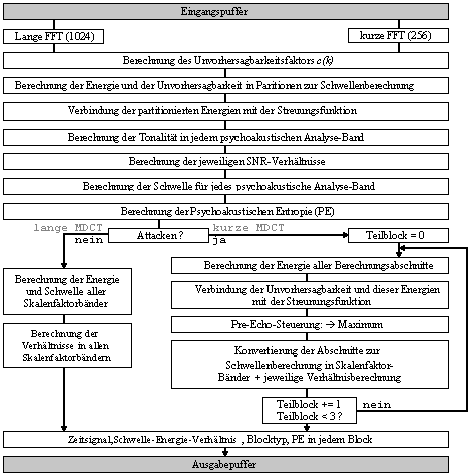
2.1.2 Psychoakustisches Modell 2 fuer
MPEG
Berechnung des
komplexen Spektrums der Schaltlänge des
Eingangssignals Berechnung der
vorhersagenden Werte (Amplitude und Phase) für den aktuellen Block von
Abtastwerten Berechnung des
Faktors der Unvorhersagbarkeit Berechnung des
Tonalitätsindexes im schmalen Teilband der Analyse Berechnung der
allgemeinen Maskierungsschwelle für das schmale Teilband der
Analyse Berechnung des
Signal-Maske-Verhälnis im breiten Teilband der
Signalcodierung Berechnung des komplexen
Spektrums der Schaltlänge des Eingangssignals Die psychoakustischen Effekte werden hier
ausschließlich im Frequenzbereich modelliert. Daher ist zunächst eine
Umsetzung in den Frequenzbreich notwendig. Dafür wird eine diskrete
Fouriertransformation (DFT) angewendet. Diese wird direkt aus dem Block
des PCM-Eingangssignales berechnet. Um eine Verwaschung des Spektrums zu
vermeiden, wird eine Fensterfunktion verwendet. Die Fensterlänge berechnet
sich wie folgt:
Die
Berechnung der Spektralkomponenten der DFT erfolgt mit folgender
Formel: Bei
einer Schaltlänge von 1024 Abtastwerten haben wir somit 512 komplexe
SpektralkomponentenX(k)=a(k)+jb(k).
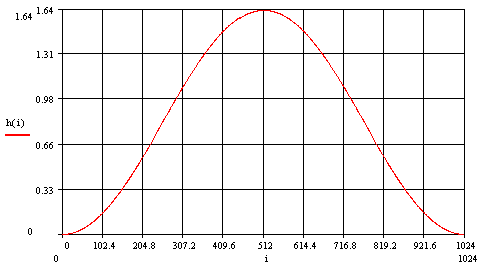
Die Koeffizientendes Hann-Fensters (siehe Abb.21) gehen als
Faktor ein, um Fehler der Transformation zu verkleinern. Sie berechnen
sich wie folgt: Als
nächstes wird für jede Spektralkomponente die Betrag-Phase-Darstellung,
alsor(k)und j(k)
berechnet. Nach dieser Berechnung werden die Spektralanteile bei
Bedarf so normiert, daß der höchste DFT-Wert der Spektralkomponenten dem
Pegel von 96dB entspricht. Berechnung der vorhersagenden
Werte (Amplitude, Phase) für den aktuellen Block Im Speicher des Codierers sollen die Betrags- und
Phasenwerte der zwei vorausgegangenen Spektralkomponenten erhalten werden.
Mit Hilfe dieser Spektraldaten werden die entsprechenden Werte für die
neue Spektralkomponente des aktuellen Blocks sozusagen vorausberechnet.
Dies geschieht durch folgende Formel:
Berechnung des Faktors der
Unvorhersagbarkeit Mit Hilfe der vorhergesagten Spektralwerte
soll nun der Faktor zur Unvorhersagbarkeit c(k)berechnet werden. Dies geschieht wie
folgt: Diese Formel gilt für alle
Spektralkomponenten der kurzen DFT (N=256). Bei der langen DFT wirdc(k) nur für
die ersten sechs Spektralkomponenten berechnet. Für die übrigen Blöcke
gilt das Minimum aus allenc(k) der kurzen DFT. Der Faktor zur
Unvorhersagbarkeit berücksichtigt den Zusammenhang zwischen den aktuellen
und den zwei vorhergehenden Abtastwerten. Durch ihn kann eine Aussage über
den Rauschgehalt des Signals innerhalb eines Teilbandes der Analyse
gemacht werden. Ist der Wert nahe 0, so war die Vorhersage gut. Bei
schlechter Vorhersage liefert dieser Faktor Werte um 0.5 bis 1. Man
bezeichnet diesen Faktor auch als Chaosmaß (MOC-measure of chaos). Durch
die Berechnung vonc(k)lassen sich noch weitere Besonderheiten des
Signalspektrums erkennen. Bei der DFT-Berechnung treten Fehler auf, welche
mit dem Effekt von Gibbs verbunden sind. Dieser wirkt sich so auf die
Phasen so aus, daß beispielsweise bei drei Blöcken das Eingangssignal
gleich ist. Dabei istc(k) natürlich genau Null.Die Gewichtung bzw. Bedeutung dieses Faktors für
jedes Teilband der Vorhersage ergibt sich aus folgender Formel: Die Werte der spektralen Grenzen sind in
entsprechenden Tabellen(nach MPEG 11172-3) für jede Abtastfrequenz
angegeben. Der Wertc(k)wird für die gesamte Bandbreite des Signals
(0..20kHz) berechnet, um das bestmögliche Ergebnis zu gewinnen. Auf Kosten
der Qualität läßt sich diese Berechnung aber auch auf die Frequenzen bis 7
oder gar 3kHz reduzieren. Dabei wird der Wert vonc(k) überall
auf 0.3 eingestellt. Berechnung des Tonalitätsindexes im schmalen Teilband
der Analyse Diese Etappe unterteilt sich wiederum in 5
Schritte (a-e): a)
Berechnung der Intensität in jedem schmalen Teilband der
Analyse In diesem Schritt werden die vorläufigen
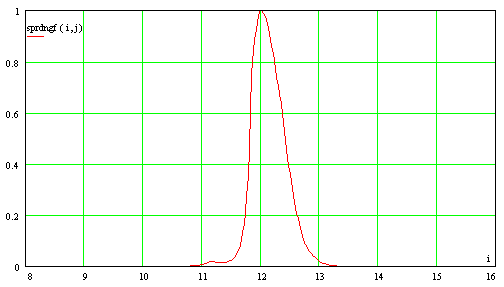
Intensitätene(b) des Signals wie folgt berechnet: b)
Berechnung der sogenannten “Streuungsfunktion”
c)
Erfassung von Intensität und Unvorhersagbarkeitsmaß in den
benachbarten Teilbändern Der Einfluß der Spektralkomponenten in den
benachbarten schmalen Teilbändern auf die Berechnungsresultate der
derzeitigen Teilbandanalyse b zeigt sich bei der Neuberechnung der
Signalintensitäte´(b) und des Unvorhersagbarkeitsfaktorsc´(b): (fehlende Formel) d) Berechnung der normierten Intensitätswerte und
Unvorhersagbarkeitsmaße Da der Unvorhersagbarkeitsfaktorc´(b) von der
Signalintensität beeinflußt wird, muß er durche´(b)
renormiert werden. Der neue Chaosfaktor ergibt sich aus folgender
Formel: Aufgrund der nicht normierten Natur der
Streuungsfunktion solltee´(b) ebenfalls renormiert und somit die
normierte Intensität des Signalsen(b) berechnet werden. Dabei ist der
erste Faktor der Normierungskoeffizient. e) Berechnung des
Tonalitäsindexes Wie bereits erwähnt, war die Vorhersage für
die Spektralwerte gut, wenn das Chaosmaßcb(b) Werte
um Null beinhaltet. Bei Werten um 0,5 bis 1 war die Vorhersage schlecht.
Johnston entwickelte eine logarithmische Operation, mit der er aus dem
Chaosmaß den Tonalitätsindexa(b)
erhält. Dieser Wert bestimmt die Näherung des Signals
im schmalen Teilband der Analyse b an ein tonales [a(b)=1]
oder rauschartiges [a(b)=0]
Signal. Der Tonalitätsindex liegt ausschließlich zwischen 0 und
1. Berechnung der allgemeinen Maskierungsschwelle für
das schmale Teilband der Analyse Zunächst wird das Signal-Rausch-Verhältnis (SNR) für
jedes Teilband der Analyse b berechnet. Dieses Verhältnis stellt den
verallgemeinerten Wert des Maskierungsmaßes dar und gibt den im Teilband
erlaubten Quantisierungsfehler an. Die Berechnung sieht folgendermaßen
aus: Das Ergebnis
dieser Gleichung liefert also im Prinzip den Wert des zulässigen
Quantisie-rungsrauschens. Die Größe des Verdeckungsmaßes berechnet sich
wie folgt: Das allgemeine
Verdeckungsmaß berechnet sich also aus zwei anderen, eines für den Fall,
daß der Ton das Rauschen maskiert (M1), ein anderes, falls das Rauschen
den Ton mit der FrequenzF maskiert (M2). Von der GrößeSNR(b) kann
man relativ einfach zu analogen Verhältnissen bei linearen Maßeinheiten
übergehen. Die folgende Formel errechnet das Leistungsverhältnis von
Tonalität und Rauschen der Analyse b des Teilbandes. Damit kann nun für
jede Spektralkomponente der zulässige Wert des Quantisierungs-rauschens
berechnet werden, bei dem das Rauschen durch das nützliche tonale Signal
maskiert wird. Die aktuelle Schwellenintensität für jede Komponente k
innerhalb der spektralen Grenzen berechnet sich wie folgt: Für die endgültige
Hörschwelle des maximal zulässigen Quantisierungsrauschens kann man für
jede Spektralkomponente noch die Absoluthörschwelle Berechnung des Signal-Maske-Verhälnis im breiten
Teilband der Signalcodierung Diese Etappe besteht wiederum aus 3
Schritten: a. Berechnung der maximal
zulässigen Rauschleistung im Teilband In diesem Schritt werden aus den 57 schmalen
Teilbändern der Analyse b die 32 breiten Teilbänder n für die Codierung
gebildet. Die Breite eines solchen Teilbandes beträgt 750 Hz. Der minimale
Wert der Rauschleistung im breiten Teilband n entsprechend der Hörschwelle
berechnet sich folgendermaßen: b. Berechnung der Leistung des
tonalen Signalanteils im Teilband c. Berechnung des Signal-Maske-Verhältnis Das Signal-Maske-VerhältnisSMR(n) wird
für jedes Teilband n berechnet und gibt jeweils den erlaubten
Quantisierungsfehler an. 2.1.3 Psychoakustisches Modell des
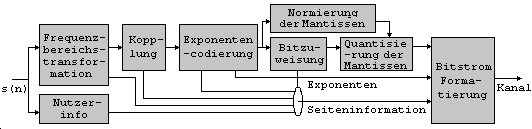
AC-3-Systems Bei diesem System ist das Psychoakustische Modell mit
in die Bitzuweisungseinheit integriert. Die Bitzuweisungsprozedur
analysiert die Spektralhülle des Audiosignals (Exponentensatz) und liefert
die Bitanzahl für jede Mantisse von Transformations-koeffizienten. Diese
Prozedur basiert auf psychoakustischen Maskierungseffekten. Die Maskierung
bezieht sich also auf den Fakt, daß das menschliche Ohr leisere Töne in
Frequenznähe lauterer Töne nicht oder nur sehr schwach wahrnimmt. In
diesem Fall ist es möglich, die sehr stark hörbaren Töne mit maximaler und
die weniger hörbaren Töne mit geringeren Bitraten darzustellen. Das
Psychoakustische System des AC-3-Systems arbeitet ausschließlich mit einem
Satz von Exponenten, welche die Eingangssignale der Bitzuweisungseinheit
darstellen. Die Ausgabe dieser Prozedur ist ein Feld von
Bitzuweisungszeigern, welche Informationen über die Bitanzahl für jede
Mantisse von Transformationskoeffizientenk
enthält.Der erste Schritt dieses
Algorithmus ist die Berechnung der SpektraldichtePSD(power-spectral density). Dies geschieht durch
Exponentenmapping nach folgender Formel: Der dynamische Bereich der PSD-Werte von 0 bis 3072
stellt den Bereich von 0 bis 144dB dar. Alle weiteren Berechnungen
beziehen sich auf diese Skale (0 bis 3072). Damit liegt die Auflösung bei
144dB/3072=0,046875dB. Die Nutzung ganzzahliger Werte ist nützlich für die
technische Implementation des Algorithmus. Die AC-3-Bitzuweisung
beinhaltet keine komplizierten mathematischen Operationen, sondern nutzt
stattdessen die “look up table”-Technik. Dies erlaubt eine geringe
Komplexität der Berechnungen und erhöht somit die Geschwindigkeit dieser.
Der nächste Schritt der Bitzuweisungsprozedur ist die Konvertierung des
Blocks mit den PSD-Werten in ein Barkspektrum. Dies geschieht durch
Unterteilung des “Energie”-Spektrums in mehrere Frequenzbänder und die
Integrierung der Werte in jedem Band. Die Bänder sind ungleichförmig,
entsprechend der kritischen Bandbreiten nach E.Zwicker (1). Die
AC-3-Bänder werden definiert durch die zentrale Frequenz eines kritischen
Bandes, bei einer unteren Grenze von 94Hz. Durch die jeweilige Betrachtung
der halben Bandbreite wird eine genauere Annäherung erreicht. Die Bänder
oberhalb von 2440Hz (ab dem 26 kritischen Band) variieren zwischen Ľ und ľ
der Bandbreite. Die PSD-Werte werden auf einer linearen Frequenzskale
berechnet. Durch diese Festlegung befinden sich ab dem 26.Frequenzband
mehr als nur ein PSD-Wert pro Band. Die Summierung zu einem repräsentativen PSD[k]-Wert in
jedem Band erfolgt durch logarithmische Addition, nach folgender
Formel: Wie schon erwähnt, werden mögliche Ergebnisse nicht
ausgerechnet, sondern aus entsprechenden Tabellen bezogen.Als nächstes folgt die Berechnung der
sogenannten “Reizungsfunktion”. Dazu wird der Prototyp der
Streuungsfunktion nach Schroeder genutzt. Diese Funktion modelliert die
Maskierungseffekte und wird durch einen Satz von Parametern definiert.
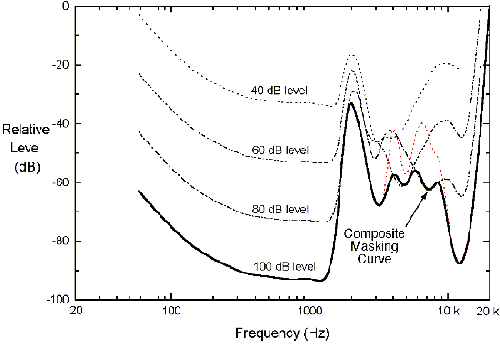
Dabei werden experimentelle Maskierungsdaten von Fielder und Ethmer
kombiniert. Man erhält dadurch Maskierungskurven, welche relativ zu festen
Maskierungsleveln (40-100dB SPL) normiert werden müssen. Die
Maskierungskurven werden relativ zum Level des Maskierungssignals normiert
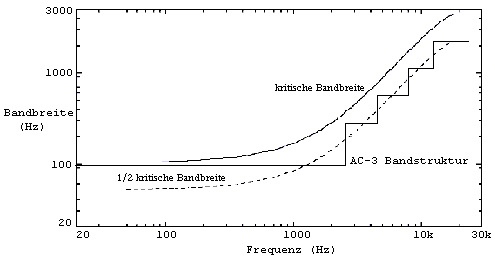
und auf der Frequenzskale ausgedrückt, entsprechend der AC-3-Bandstruktur
(Abb. 23). Die daraus resultierende Maskierungskurve charakterisiert dann
die Streuungsfunktion und den Variationsbereich der
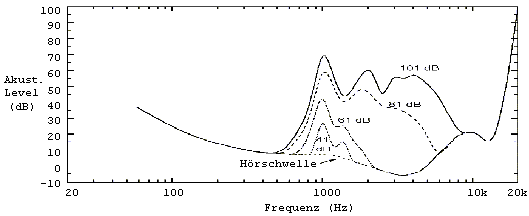
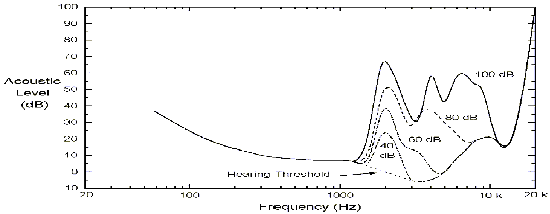
Parameterwerte. Die Abbildungen 24 und 25 stellen die Ergebnisse
eines Maskierungsversuches bei 1 und 2 kHz dar. Das Experiment nutzt zur
Maskierung ein Sinussignal und bestimmt die JND-Level der berechneten
kritschen Bandbreite des Rauschsignals.Die Normierung zur relativen Maskierungsschwelle kann
durch folgende Prozedur vollzogen werden: Das Resultat der Normierung der 2kHz-Maskierungskurve
zeigt Abb.26. Eine “zusammen-gesetzte Maskierungskurve” wurde konstruiert
aus den Minima von den vier relativen Maskierungsschwellen. Dieselbe
Prozedur wurde für andere Maskierungsfrequenzen angewendet (0.02, 0.05,
0.1, 0.2, 0.25, 0.5, 1,2, 4, 8 kHz), woraus
sich ein Satz von zehn zusammengesetzten Kurven ergibt. Letztendlich werden die Kurven für alle
Frequenzen mit Maskierungsdaten zu einer einzigen “worst
case”-Streuungsfunktion zusammengefaßt. Dies geschieht mit Hilfe des
Entwurfs der Maskierungskurven auf der Frequenzskale der relativen
AC-3-Bandangaben.Das
Audiospektrum von 0 bis 700Hz wird in zwei Regionen unterteilt. Unterhalb
200Hz nimmt AC-3 keine Nachmaskierung an. Zwischen 200 und 700Hz wird dies
nur nach signifikanten Komponenten oberhalb 200Hz angenommen. Für
Frequenzen oberhalb von 700 Hz wird immer Aufwärtsmaskierung
angenommen.Die Variation der
Form von vier zusammengesetzten Maskierungskurven für Töne mit 0.5, 1, 2
und 4 kHz zeigt Abb.27. (fehlende Abbildung) Die Hülle der Maskierung für jede gebildete Kurve
kann durch zwei Segmente angenähert werden. Die Streuungsfunktion ist
definiert als Punkt-zu-Punkt-Maximum zweier Segmente über die Frequenz.
Diese Technik entspricht nicht der traditionellen Darstellung der
Streuungsfunkton, in der nur einzelne lineare Segmente mit erhöhter
Frequenz benutzt werden. Die Zwei-Segment-Annäherung erreicht eine
genauere Modellierung bei starken angrenzenden Maskierern, aber weniger,
jedoch ausreichende, bei frequenzmäßig weiter entfernten Maskierern.
Vormaskierung ist weniger bedeutend und wird daher im
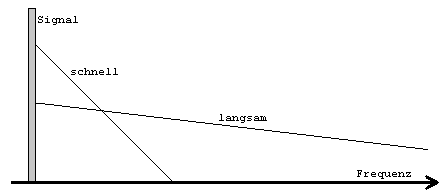
AC-3-Maskierungsmodell nicht betrachtet. Das erste Segment (schnelle Maskierung) beginnt am
Frequenzband der maskierenden Komponente und fällt mit steigender Frequenz
ziemlich steil ab, jedoch ist der Offset vom maximalen Signallevel
verhältnismäßig gering. Das zweite Segment (langsame Maskierung) beginnt
ebenfalls am Frequenzband der maskierenden Komponente, jedoch mit einem
größeren Offset und einer nicht so steilen Flanke.Der Codierer wählt einen Prototyp der
Streuungsfunktion aus, welcher besser in den Bitstrom der vorläufigen
Bitzuweisung paßt. Für die Berechnung der Reizungsfunktion kann ein Modell
verwendet werden, welches zwei lineare Filter beinhaltet, welche parallel
miteinander verbunden sind. Jeder Filter entspricht der Charakteristik
eines Segments. Der letztendliche “Reizungs”-WertE(k) des
Bandesk
ist der größere der zwei Filterergebnisse. Dies drückt folgende
Gleichungskombination aus: P(k) –
logarithmisches
Amplituden-Spektrum Im AC-3 Algorithmus wird also diese
Addition durch den maximalen Operator ersetzt. Der letzte Schritt in
diesem Algorithmus ist der Maskierungsvergleich. Dies geschieht durch die
Subtraktion der globalen Maskierungsschwelle vom originalen Spektralfeld,
um daß SNR-Verhältnis (signal-to-noise-ratio) für jeden einzelnen
Transformationskoeffizienten zu erhalten. Das Feld der SNR-Werte wird in
ein Feld von Bitzuweisungszeigern konvertiert, wieder unter Nutzung einer
entsprechenden Tabelle. An dieser Stelle erfolgt die eigentliche
Bitzuweisung, wobei die Anzahl der verfügbaren Bits für die Quantisierung
der Mantissen von der vorgegebenen Bitrate, der Exponentenstrategie und
der Anzahl der für die Seiteninformation notwendigen Bits abhängen. Die
Bits werden alle global von einem sogenannten Bitpool an alle Kanäle
zugewiesen. Damit sollen die Erläuterungen zum AC-3-Modell in dieser
Arbeit reichen. 2.2 Beschreibung des Kompressionsalgorithmus ^ Die MPEG-1-Struktur enthält drei Layer hin zur
verbesserten Komplexität, Verzögerung und Ausgabequalität. Jeder Layer
enthält die Funktionsblöcke des jeweils tieferen Layers. Layer 1 und 2
wurden im ersten Abschnitt kurz beschrieben, eine ausführliche
Beschreibung von Layer 3 soll dieser Abschnitt liefern und somit in die
Themenspezialisierung dieser Diplomarbeit münden. Der Layer 3 erreicht
Leistungsverbesserungen durch verschiedene zusätzliche wichtige
Mechanismen, welche auf das Layer 1/2-Fundament aufgesetzt wurden, wie
beispielsweise eine Hybridfilterbank zur besseren Frequenzauflösung sowie
einer besseren Annäherung an das Verhalten der kritischen Bänder und eine
verfeinerte Bitzuweisungs- und Quantisierungsstrategie, welche auf
ungleichförmiger Quantisierung, Analyse durch Synthese und
Entropiecodierung beruht. Diese neuen Merkmale ermöglichen eine reduzierte
Bitrate bei verbesserter Qualität gegenüber den
Vorentwicklungen.Es werden nun
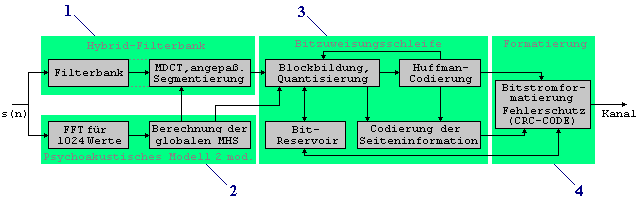
ausführlich Codierer und Decodierer des Codierungsalgorithmus zum
MPEG-Standard ISO/IEC 11172-3 Layer 3 beschrieben und anschaulich
erklärt. Hier noch einmal das Blockdiagramm in seinen
Bestandteilen, die in der gegebenen Reihen-folge beschrieben werden
sollen. Um bei der nun folgenden sehr detaillierten
Beschreibung der einzelnen Bestandteile nicht den Überblick zu verlieren,
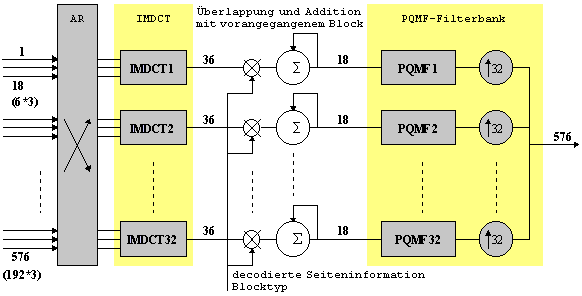
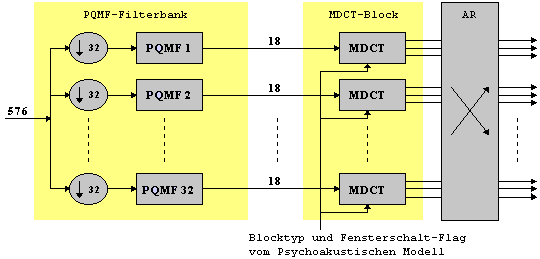
sei hier noch einmal ein knapper Überblick gegeben.Das Signal wird zunächst durch die Filterbank in 32
Teilbänder zerlegt. Jedes Teilband wird dann mit 18 Koeffizienten
dargestellt. Dies geschieht durch Zuführung dieser 32 Teilbänder an eine
MDCT, woraus sich dann jeweils 18 Transformationskoeffizienten ergeben.
Durch adaptive Fensterumschaltung in der MDCT können die
Spektralkoeffizienten eines Teilbands bis auf 6 reduziert werden (höhere
zeitliche Auflösung). Mit Hilfe der Analyse-durch-Synthese Technik werden
die Spektralkoeffizienten, gesteuert durch das psychoakustische Modell,
codiert. Dabei wird der Quantisierungsfehler mit der Maskierungsschwelle
verglichen und die Quantisierung entsprechend angepaßt. Die quantisierten
Spektralkoeffizienten werden nun einer Huffman-Codierung und einer
Lauflängencodierung unterzogen. Bei diesen Entropiecodierungen werden
statistische Effekte ausgenutzt, also häufig vorkommende Werte mit
Codeworten geringerer Länge codiert. Zur Vermeidung von Artefakten
verwendet Layer-3 Kurzzeitbuffer. Nicht benötigte Bits werden aufgehoben
und an kritischen Stellen verwendet (kurzzeitig höhere Datenrate). Die
Größe der Buffer hängt davon ab, wie kritisch die Verzögerungszeit ist.
Die Übertragung der Daten erfolgt nach der Codierung und Formatierung von
Spektralkoeffizienten und Seiteninformation. 2.2.1.1
Hybrid-Filterbank Die Filterbank wurde mit dem Ziel entwickelt,
Kompatibilität zu Layer 2
bei verbesserten Merkmalen zu bieten. Die Ausgabewerte eines jeden der 32
Kanäle der Polyphasenfilterbank,
welche auch von Layer
2 genutzt wird, durchlaufen eine
MDCT mit jeweils einerAusgabe
von 18 Kanälen. Somit beträgt die maximale Anzahl der
Filterbank-Ausgabewerte 32x18=576. Aufgrund dieser geringen Anzahl kann eine direkte
Implementation der Filterbank genutzt werden, ohne wesentliche
Strapazierung der Komplexität. Diese liefert unterschiedliche
Zeit/Frequenz-Auflösungen bei verschiedenen Frequenzen zur Simulierung des
menschlichen Gehörs. Dies führt zum maximalen Transformationsgewinn für
die eingesetzten Signale.Die
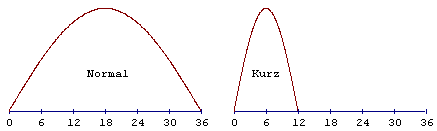
Fensterlänge beträgt 36 bei langen Fenstern und 12 bei kurzen Fenstern.
Zur Teilbandanalyse wird eine Hybrid-PQMF-Filterbank (PQMF – Polyphase
Quadrature Mirror Filter) genutzt, um die Breitbandsignale mit der
Abtastfrequenz Die Teilbandanalyse beinhaltet folgende Schritte
(1): -
Eingangssignal von 32 Abtastungen -
Bildung eines Eingangs-Abtastungs-VektorX für die
512 Elemente. Die 32 Audio-Abtastwerte werden auf die Postionen 0 bis 31
gesetzt, der neuste auf Position 0, der letzte auf Position
31. -
FenstervektorX von VektorC. Die
Koeffizienten werden gefunden in [1, pp.68-69] -
Berechnung der 64 Werte -
Berechnung der 32 Teilband-Abtastwerte Die Ausgabe der Polyphasen-Filterbank ist die Eingabe
zur Unterteilung durch die MDCT, entsprechend der Ausgabe des
psychoakustischen Modells (Fensterschaltungs-Flag und Blocktyp) werden
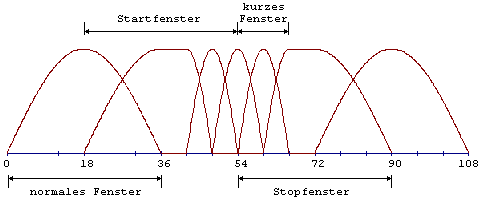
Fenster und Transformationstypennormal,kurz, Start oderStop gewählt. Eine Fensterlänge von 1152 Abtastwerten entspricht
24ms bei einer Abtastfrequenz von 48kHz. Alle Quantisierungsfehler im
Frequenzbereich sind über diese zeitliche Ausdehnung verteilt. Signale,
welche Attacken oder ähnliche Ereignisse (Triangel, Kastagnette) im
Zeitbereich enthalten, resultieren in hörbaren Pre-Echos. Aus diesem Grund
gibt es die Möglichkeit der dynamischen Veränderung der Fensterform. Diese
Technik basiert auf dem Effekt, daß Terme, welche durch Teilbandabtastung
erzeugt wurden, im Frequenzbereich der MDCT auf die Hälfte des Fensters
reduziert werden. Die
18 Ausgabewerte einer Granule und die 18 Ausgabewerte der vorhergehenden
Granule werden zusammengefaßt zu einem Block von 36 Abtastwerten. Hier die
Berechnung des Blocktyps “normal” für die 36-Punkt-MDCT: Die Werte des Blocktyps “kurz” für
die 12-Punkt-MDCT berechnen sich wie folgt: Die
Grafen der beiden MDCT-Funktionen für lange und kurze Fenster zeigt
Abb.32. Um zwischen dem normalen und kurzen Blocktyp umschalten zu können,
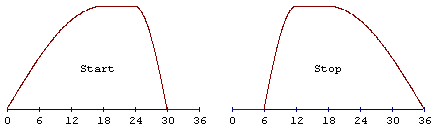
wird dieses hybride “Start”-Fenster ... und dieses “Stop”-Fenster genutzt: Die
Grafen dieser beiden MDCT-Funktionen für das Start- und Stopfenster zeigt
Abb.33. Der analytische Ausdruck der MDCT ist
folgender: Die
MDCT bietet offensichtlich den Vorteil überlappender Zeitfenster (50%),
bei Erhaltung der kritischen Abtastungen. Dank der überlappenden
Eigenschaft ist eine gute Voraussetzung für die spätere Quantisierung
gegeben. Artefakte zwischen den Transformationsblöcken können so leicht
erkannt und entfernt werden. 2.2.1.2
Psychoakustisches Modell 2 Für die Berechnung der psychoakustischen Parameter
kann entweder Sämtliche Punkte, welche in diesem Abschnitt nicht
angesprochen werden, entsprechen denen im herkömmlichen Psychoakustischen
Modell 2. Es wird nur auf Modifikationen dieses Modells eingeganden. Das
Modell wird zweimal parallel berechnet. Eine Berechnung wird mit einer
Länge von 192 Abtastungen (angewendet bei kurzen Blöcken) durchgeführt,
die andere mit einer Schaltlänge von 576 Abtastungen. Für die Schaltlänge
von 192 Abtastungen müssen die Blocklänge der FFT auf 256 geändert und die
Parameter entsprechend geändert werden.Ein wesentlicher Unterschied besteht in der Wahl der
Streuungsfunktion, welche in folgender Formel dargestellt ist (nur Werte
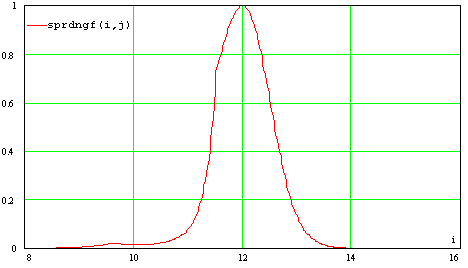
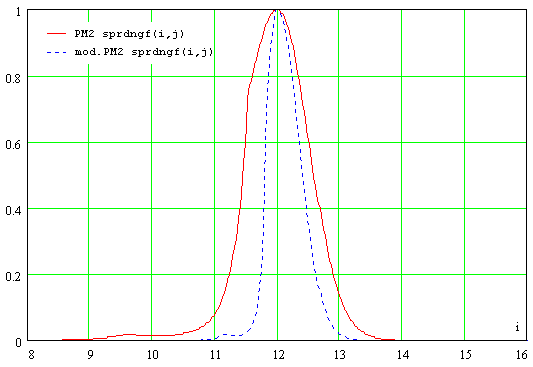
über Als
Beispiel sei in Abb.37 die Streuungsfunktion mit dem mittleren
Frequenzwert von 12Bark dargestellt. Eindeutig erkennbar ist, daß die
Streuungsfunktion ihren Maximalwert hat, wenn aktueller Frequenzwert i und
der Mittelwert j übereinstimmen. Die Graf fällt zu beiden Seiten hin ab,
so daß man wieder von einer filtrierenden Eigenschaft der Funktion
sprechen kann. Als Vergleich sei in Abb.38 die Streuungsfunktionen
des einfachen Psychoakustischen Modells 2 dargestellt, ebenfalls mit einem
mittleren Frequenzwert von 12 Bark. Es ist deutlich erkennbar, daß bei dem
modifizierten Psychoakustischen Modell eine feinere Filtrierung
durchgeführt wird. Dies wird durch die Alternative für tmpx im ersten
Schritt der Formel zur Streuungsfunktion [58] erreicht. Beim herkömmlichen
Psychoakustischen Modell 2 ist tmpx immer 1,5(j-i).Die Größe des Verdeckungsmaßes berechnet sich auch
beim modifizierten Psychoakustischen Modell 2 wie folgt: Das allgemeine Verdeckungsmaß berechnet sich also aus
zwei anderen Verdeckungsmaßen, eines für den Fall, daß der Ton das
Rauschen maskiert (M1), ein anderes, falls das Rauschen den Ton maskiert
(M2). Diese Werte werden in diesem modifizierten psychoakustischen Modell
einfach auf 18 und 6 dB gesetzt.
Bei der Unvorhersagbarkeitsberechnung gibt es folgende weiteren
Abänderungen: Die Berechnung der metrischen
Unvorhersagbarkeit Die Psychoakustische Entropie wird durch das
Verhältnis thr/eb berechnet, wobei thr die Schwelle und eb die Energie
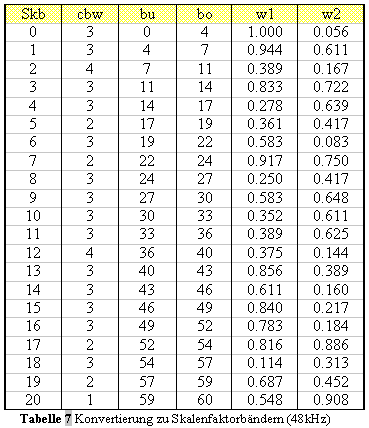
ist: Die Schwelle wird nicht über die FFT-Linien verteilt.
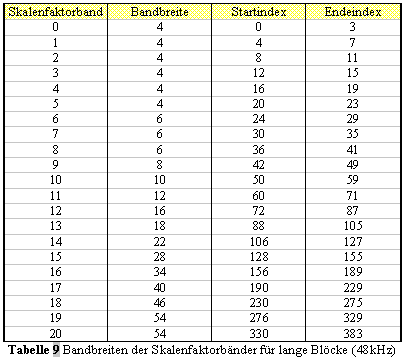
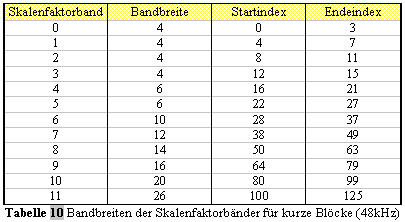
Die Schwellenberechnungs-partitionen werden direkt zu Skalenfaktorbänder
konvertiert. Die erste Partition, welche zum Skalenfaktorband addiert
wird, wird mit w1 bezeichnet, die letzte mit w2 (siehe Tabelle 7 für
Abtastrate 48kHz). Die Tabelle beinhaltet ebenfalls die Partitionsnummer
cbw, konvertiert zu einem Skalenfaktorband (ausgenommen die erste und
letzte Partition). bo und bu werden ebenfalls für die Konvertierung zu
Skalenfaktorbändern genutzt. Für kurze Blöcke wird eine vereinfachte
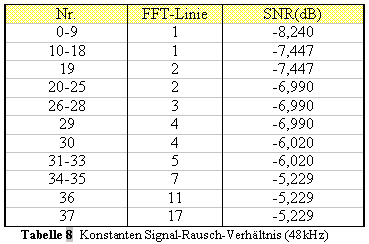
Version der Schwellenberechnung (konstantes Signal-Rausch-Verhältnis)
angewendet. Die Konstanten sind in Tabelle 8 zu finden (SNR ). Das
Psychoakustische Modell ist im Prinzip ein Werkzeug zur Codierung eines
digitalen Signals und kann daher niemals nur für sich selbst betrachtet
werden. Der direkte Einfluß auf andere Abschnitte des Codierers lassen
gewisse Berechnungsabschnitte als Bestandteil des Psychoakustischen
Modells erscheinen, wie beispielsweise FFT und MDCT. Die eigentliche
Codierung erfolgt jedoch erst in der Bitzuweisungsschleife, deren
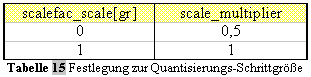
Beschreibung nun folgt. Die Skalenfaktoren werden logarithmisch
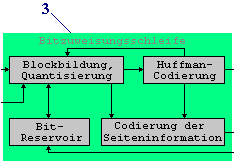
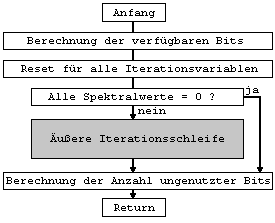
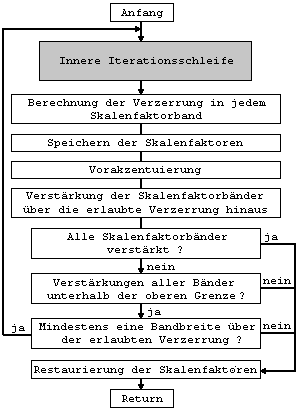
quantisiert. Die Bitzuweisungsschleife ist in drei Ebenen
unterteilt. Die Hauptebene wird als “Schleifen-Rahmenprogramm” bezeichnet.
Dieses Rahmenprogramm enthält eine innere und eine äußere Schleife. Die
folgenden Flußdiagramme in Abb.39 bis Abb.41 stellen diese drei Ebenen
dar. Die
Schleifenmodule quantisieren einen Vektor von Spektraldaten in einem
iterativen Prozeß entsprechend der verschiedenen Anforderungen. Die innere
Schleife quantisiert den Eingangsvektor und erhöht die
Quantisierungsschrittgroesse, bis der Ausgabevektor mit der verfügbaren
Anzahl an Bits codiert werden kann. Nach der Vollendung der inneren
Schleife kontrolliert eine äußere Schleife die Verzerrung eines jeden
Skalenfaktorbandes. Überschreitet ein Skalenfaktorband die erlaubte
Verzerrung, so wird dieses Band verstärkt und die innere Schleife erneut
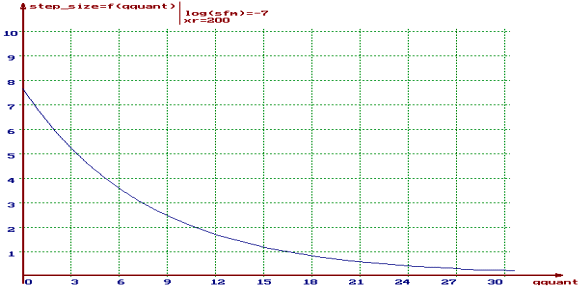
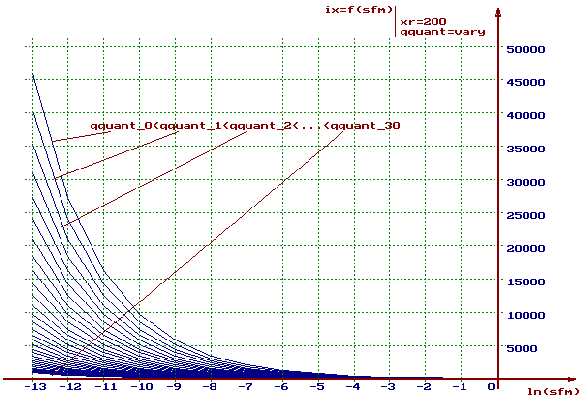
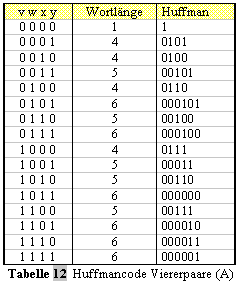
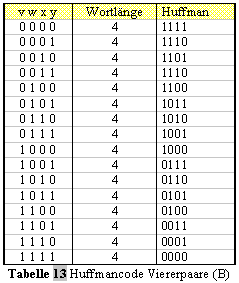
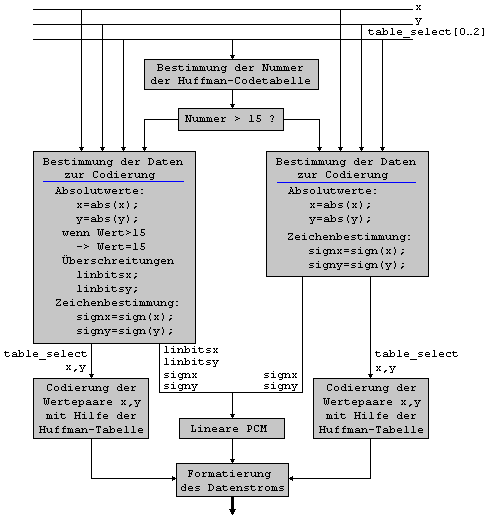
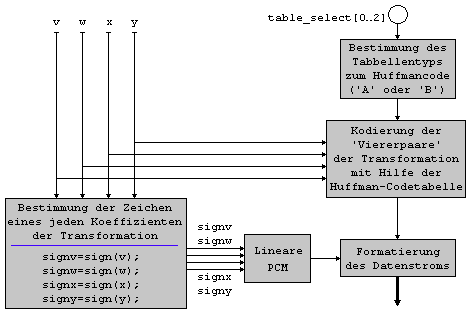
aufgerufen. ( fehlender Text Diplomarbeit S.67-71) ( fehlender Text Diplomarbeit S.72-73) ( fehlender Text Diplomarbeit S.75) ( fehlender Text Diplomarbeit S.75-76) 2.2.1.4
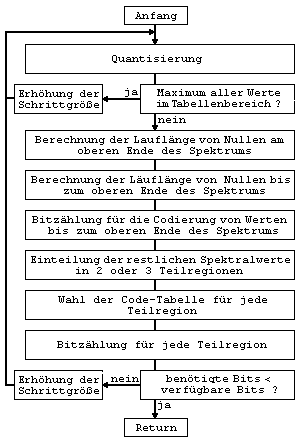
Bitstromformatierung ( fehlender Text Diplomarbeit S.78) ( fehlender Text Diplomarbeit S.78-80) ( fehlender Text Diplomarbeit S.80-81) ( fehlender Text Diplomarbeit S.81-83)
2.2.2 Der Decodierer ( fehlender Text Diplomarbeit S.84-85) ( fehlender Text Diplomarbeit S.85-87) ( fehlender Text Diplomarbeit S.87) 3.2 Testung des
Programms Mit ein paar Sätzen soll diese Arbeit nun
ihren Abschluß finden. In umfassender Weise wurden Beschreibungen
verschiedener Algorithmen zur digitalen Codierung von Tonsignalen
geliefert. Dabei wurde neben tiefgreifenden Erläuterungen, speziell des
MPEG-Standards ISO/IEC 11172-3 Layer 3, auch auf Grundlagen der
Psychoakustik eingegangen. Das Psychoakustische Modell 2 wurde sowohl in
seiner ursprünglichen Form, wie in Layer 1 und 2 verwendet, sowie auch als
Modifikation, genutzt in Layer 3, behandelt. Das zur Demonstration des
Codierungsvorganges entwickelte Programm ermöglicht durch eine
selbsterklärende Benutzeroberfläche eine verständliche Darstellung der
einzelnen Codierungsetappen. Dabei können die zu codierenden Wav-Signale
(PCM) frei gewählt werden. Eine ausführliche Dokumentation zum Programm
und zur Testung desselben runden diese Arbeit ab. Die Ausarbeitungen sind
mit dieser Arbeit nicht abgeschlossen, sondern sollen auch in Zukunft
ergänzt und erweitert werden.
(1) Publikation: Coding of Moving Pictures and
Associated Audio – ISO/IEC 11172-3, 1993 ISO/IEC Copyright-Office
Switzerland (2) Scott Nathan Levin: Audio Representations for
Data Compression and Compressed Domain Processing, Dissertation, 1999
Stanford University (3) ISO/IEC MPEG-2 Advanced Audio Coding, Journal
of the Audio Engineering Society (AES), Volume 45 Number 10, 1997,
S.789ff. (4) K. H. Brandenburg: Overview of MPEG-Audio –
Current and Future Standards for Low-Bit-Rate Audio Coding, Journal of the
Audio Engineering Society (AES), Volume 45 Number ˝, 1997, S.4ff. (5) Subjective Evaluation of State-of-the-Art
Two-Channel Audio Codecs, Journal of the Audio Engineering Society (AES),
Volume 46, Number 3, 1998, S.164ff. (6) Carstens, Matthias: Musik kompakt –
Audiokompression mit MPEG Layer-3, c’t-Magazin, Heft 21, 1998, S.242 ff.
(7) Hompage des Fraunhofer-Instituts für
integrierte Schaltungen: http://www.iisfhg.de (8) Freyer, Ulrich: DAB – Digitaler Hörfunk, 1997
Verlag Technik GmbH Berlin (9) Ted Painter, Andreas Spanias: A Review of
Algorithms for Perceptual Coding of Digital Audio Signals, Paper, 1997
Arizona State University (10) Bernd Edler, Heiko Purnhagen, Charalampos
Ferekidis: ASAC - Analysis/Synthesis Audio Codec for Very Low Bit Rates,
Institut für Theoretische Nachrichtentechnik und Informationsverarbeitung,
1996 Universität Hannover (11) Bondhan Winduratna: FM Analysis/Synthesis
Based Audio Coding, Laboratorium für Informationstechnologie, 1997
Universität Hannover (12) James D.Johnston: Estimation of Perceptual
Entropy Using Noise Masking Criteria, AT&T Bell Laboratories, © 1988
IEEE (13) Aníbal Joao de Sousa Ferreira: Spectral
Coding and Post-Processing of High Quality Audio, 1998 Porto, France (14) Publikation International Standard:
Information technology – Generic coding o moving pictures associated audio
information – Part 7: Advanced Audio Coding (AAC), © 1997 ISO/IEC (15) A.V. & G.V. Frolow: Multimedia für
Windows (Russische Ausgabe), 1994 “Dialog-Mifi”-Verlag Moskau (16) Redaktion Toolbox: Visual C++ 6.0 –
Professionelle Programmierung, 1999 C&L-Verlag Vaterstetten (17) Hans Jürgen Scheibl: Visual C++ 6.0 – für
Einsteiger und Fortgeschrittene, 1999 Carl Hanser Verlag München Wien (18) Swedish Broadcasting Corporation, "ISO
MPEG/Audio Test Report", Stokholm, Jul, 1990. (19) IEC/JTC1/SC29, "Description of MPEG-4",
Document N1410, Oct.1996. (20) Y.F.Dehery, G.Stoll, and L.v.d.Kerkof,
"MUSICAM Source Coding for Digital Sound", in Symp. Rec. "Broadcast
Sessions" of the 17th Int. Television Symp.(Montreux, Switzerland, 1991
June), pp. 612-617. dB: Abk. für Dezibel. Logarithmische
Maßeinheit, z.B. eines Spannungsverhältnisses. Diplomarbeit im Netz seit
01.03.2001 |

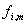 eine
hochauflösende Frequenzbewertung in der Umgebung von
eine
hochauflösende Frequenzbewertung in der Umgebung von
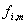 Amplituden- und
Phasenbewertung und Auswahl der Hülleninformation. Die zu
bestimmende FFT-Linie wird bestimmt durch die Berechnung der
Differenz zwischen Eingangsspektrum
Amplituden- und
Phasenbewertung und Auswahl der Hülleninformation. Die zu
bestimmende FFT-Linie wird bestimmt durch die Berechnung der
Differenz zwischen Eingangsspektrum
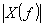 und synthetisches Spektrum
und synthetisches Spektrum
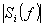 und durch Suchen des
maximalen Verhältnisses des Quadrates dieser Differenz und der
maskierenden Schwelle
und durch Suchen des
maximalen Verhältnisses des Quadrates dieser Differenz und der
maskierenden Schwelle
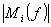 ,
berechnet aus dem Signal
,
berechnet aus dem Signal
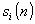 , welches aus der vorausgegangenen Spektrallinie bestimmt
wurde. Basierend auf der mittleren Frequenz
, welches aus der vorausgegangenen Spektrallinie bestimmt
wurde. Basierend auf der mittleren Frequenz
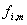 der gewählten FFT-Linie wird eine
Frequenzbewertung hergeleitet, um Frequenzparameter mit höherer
Genauigkeit als bei der FFT-Auflösung zu erhalten. Die
originale Frequenzbewertung basiert auf einem linearen
Rückschritt für Phasenwerte. Für diese
Frequenzbewertung wird zuerst das Spektrum des Restfehlersignals
der gewählten FFT-Linie wird eine
Frequenzbewertung hergeleitet, um Frequenzparameter mit höherer
Genauigkeit als bei der FFT-Auflösung zu erhalten. Die
originale Frequenzbewertung basiert auf einem linearen
Rückschritt für Phasenwerte. Für diese
Frequenzbewertung wird zuerst das Spektrum des Restfehlersignals
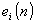 mit
mit
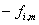 bearbeitet, durch Multiplikation mit den
komplexen Harmonien:
bearbeitet, durch Multiplikation mit den
komplexen Harmonien:
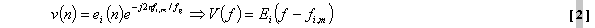
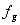 die Abtastfrequenz anzeigt. Die komplexen Ausgabewerte dieser
Operation werden durch einen Tiefpaßfilter und die
Abtastratenreduktion mit Faktor vor der Berechnung der Phasenwerte
für die resultierenden Abtastungen erreicht. Um die Phasenwerte
zu erhalten, welche das Interval überschreiten, wird für
jedes Paar zweier aufeinanderfolgender Abtastungen zuerst die
Phasendifferenz berechnet
die Abtastfrequenz anzeigt. Die komplexen Ausgabewerte dieser
Operation werden durch einen Tiefpaßfilter und die
Abtastratenreduktion mit Faktor vor der Berechnung der Phasenwerte
für die resultierenden Abtastungen erreicht. Um die Phasenwerte
zu erhalten, welche das Interval überschreiten, wird für
jedes Paar zweier aufeinanderfolgender Abtastungen zuerst die
Phasendifferenz berechnet
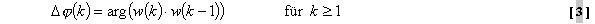


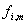 addiert werden kann,
um eine Schätzung der linearen Frequenzänderung zu
erreichen.
addiert werden kann,
um eine Schätzung der linearen Frequenzänderung zu
erreichen.

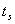 des Rahmens gibt die Offsets
des Rahmens gibt die Offsets
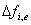 und
und
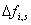 und die entsprechenden Frequenzparameter
und die entsprechenden Frequenzparameter
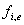 und
und
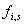 :
:
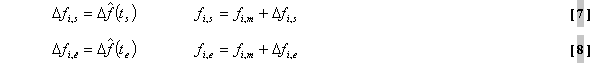
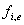 und
und
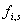 werden Amplitude und Phase der Spektrallinie
berechnet. Dies wird durch Berechnung eines komplexen
Korrelationskoeffizienten des restlichen Fehlersignals und eines
harmonischen Signals mit linearer Frequenzänderung von
werden Amplitude und Phase der Spektrallinie
berechnet. Dies wird durch Berechnung eines komplexen
Korrelationskoeffizienten des restlichen Fehlersignals und eines
harmonischen Signals mit linearer Frequenzänderung von
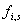 zu
zu
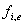 innerhalb des Rahmens realisiert. Den absoluten
Wert des Korrellationskoeffizienten gibt der Amplitudenparameter
innerhalb des Rahmens realisiert. Den absoluten
Wert des Korrellationskoeffizienten gibt der Amplitudenparameter
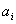 , das Argument gibt den
Phasenparameter
, das Argument gibt den
Phasenparameter
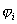 . Wenn
die Voranalyse die Hüllenparameter erzeugt hat, wird ein
zweiter Satz von Parametern
. Wenn
die Voranalyse die Hüllenparameter erzeugt hat, wird ein
zweiter Satz von Parametern
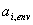 und
und
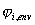 berechnet,
zusammenhängend mit dem Restfehlersignal und dem komplexen
harmonischen Signal , welches zusätzlich mit der entsprechenden
Hülle multipliziert wird. Die Startfrequenz
berechnet,
zusammenhängend mit dem Restfehlersignal und dem komplexen
harmonischen Signal , welches zusätzlich mit der entsprechenden
Hülle multipliziert wird. Die Startfrequenz
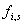 und die Endfrequenz
und die Endfrequenz
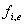 werden in der folgenden
Synthesestufe genutzt, um den Restfehler zu minimieren.
Außerdem werden diese Parameter zur Entscheidung genutzt, ob
es sich um fortlaufenden Linien handelt, von einem Rahmen zum
nächsten. Jedoch nur der arithmetische Ausdruck
werden in der folgenden
Synthesestufe genutzt, um den Restfehler zu minimieren.
Außerdem werden diese Parameter zur Entscheidung genutzt, ob
es sich um fortlaufenden Linien handelt, von einem Rahmen zum
nächsten. Jedoch nur der arithmetische Ausdruck

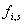 ,
,
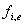 ,
,
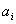 und
und
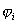 . Sind die Hüllenparameter verfügbar, so wird ein
zweites Sinussignal aus den Parametern
. Sind die Hüllenparameter verfügbar, so wird ein
zweites Sinussignal aus den Parametern
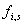 ,
,
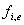 ,
,
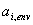 und
und
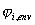 synthetisiert und mit der
Hüllenfunktion multipliziert, geliefert durch die Voranalyse.
In der Separationseinheit wird ein neues Restfehlersignal durch
Subtraktion des synthetisierten Signals erzeugt. Ist ein zweites
synthetisiertes Signal verfügbar, so wird ein zweites
Restfehlersignal berechnet. In diesem Fall wird der Parametersatz,
der zur geringsten Restfehlervarianz führt, gewählt und
entsprechend dem Restfehlersignal in den weiteren Analyseschritten
genutzt. Um den Bitstrom zu decodieren, welcher durch den
Analyse/Synthese-Codierer erzeugt wurde, sind zwei verschiedene
Decodierer verfügbar. Der Hauptdecodierer nutzt nur den
Hauptbitstrom, um die quantisierten Frequenzen- und
Amplitudenparameter der Spektrallinie zu erhalten. Die
Phasenverhältnisse werden nicht bestimmt. Der verbesserte
Decodierer nutzt den Haupt- und den erweiterten Bitstrom, um ein
Ausgabesignal zu rekonsturieren. Um die erforderliche Bitrate weiter
zu reduzieren, gibt es ein neues Konzept zur Codierung von
Parametern, welche harmonische Töne beschreiben. Dieses Konzept
basiert auf der Technik der FM (Frequenzmodulation) –Synthese,
welche gut bekannt ist in der Musik-Synthesizertechnik (10).
synthetisiert und mit der
Hüllenfunktion multipliziert, geliefert durch die Voranalyse.
In der Separationseinheit wird ein neues Restfehlersignal durch
Subtraktion des synthetisierten Signals erzeugt. Ist ein zweites
synthetisiertes Signal verfügbar, so wird ein zweites
Restfehlersignal berechnet. In diesem Fall wird der Parametersatz,
der zur geringsten Restfehlervarianz führt, gewählt und
entsprechend dem Restfehlersignal in den weiteren Analyseschritten
genutzt. Um den Bitstrom zu decodieren, welcher durch den
Analyse/Synthese-Codierer erzeugt wurde, sind zwei verschiedene
Decodierer verfügbar. Der Hauptdecodierer nutzt nur den
Hauptbitstrom, um die quantisierten Frequenzen- und
Amplitudenparameter der Spektrallinie zu erhalten. Die
Phasenverhältnisse werden nicht bestimmt. Der verbesserte
Decodierer nutzt den Haupt- und den erweiterten Bitstrom, um ein
Ausgabesignal zu rekonsturieren. Um die erforderliche Bitrate weiter
zu reduzieren, gibt es ein neues Konzept zur Codierung von
Parametern, welche harmonische Töne beschreiben. Dieses Konzept
basiert auf der Technik der FM (Frequenzmodulation) –Synthese,
welche gut bekannt ist in der Musik-Synthesizertechnik (10).
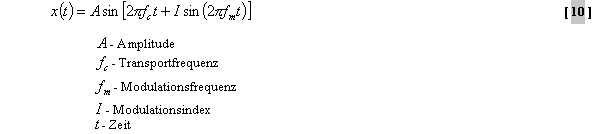

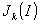 abhängt, wobei das
Argument der Modulationsindex ist. Ein einziger
FM-Synthese-Prozeß, welcher einen FM-Parametersatz
(Modulationsfrequenz, Transportfrequenz, Modulationsindex und
Amplitude) einbezieht, wird FM-Operator genannt. Verschiedene
FM-Operatoren können parallel oder in Serie geschaltet werden,
um ein komplexeres Schema zu erzeugen. Da es verschiedene
Möglichkeiten für die FM-Parameteranpassung gibt, taucht
das Problem der korrekten Anpassung der FM-Parameter für ein
gegebenes Spektrum auf. Ohne Annahmen über die Eigenschaften
der gegebenen Signale ist die Anpassung für eine optimale
Parameterkombination sehr schwierig und komplex. Um dieses nicht
lineare Problem der Parameteranpassung zu bewältigen, gibt es
eine numerische FM-Analyse zur Schätzung der FM-Parameter. Das
Hauptprinzip dieser Codierung besteht aus drei Schritten. Der erste
Schritt ist die Ermittlung der Spektralinformationen des
Eingangssignals mit Hilfe einer Voranalyse. Dann folgt die
Durchführung der FM-Analyse-Prozedur für die gewonnenen
FM-Parametersätze aus den geschätzten harmonischen
Spektrallinien. Der dritte Schritt ist die Quantisierung und
Codierung der geschätzten FM-Parameter. Bekanntlich haben
Musiksignale eine harmonische Struktur. Ihre Spektren zeichnen sich
durch diskrete Frequenzen aus, welche aus ganzen mehrfachen
Grundfrequenzen
abhängt, wobei das
Argument der Modulationsindex ist. Ein einziger
FM-Synthese-Prozeß, welcher einen FM-Parametersatz
(Modulationsfrequenz, Transportfrequenz, Modulationsindex und
Amplitude) einbezieht, wird FM-Operator genannt. Verschiedene
FM-Operatoren können parallel oder in Serie geschaltet werden,
um ein komplexeres Schema zu erzeugen. Da es verschiedene
Möglichkeiten für die FM-Parameteranpassung gibt, taucht
das Problem der korrekten Anpassung der FM-Parameter für ein
gegebenes Spektrum auf. Ohne Annahmen über die Eigenschaften
der gegebenen Signale ist die Anpassung für eine optimale
Parameterkombination sehr schwierig und komplex. Um dieses nicht
lineare Problem der Parameteranpassung zu bewältigen, gibt es
eine numerische FM-Analyse zur Schätzung der FM-Parameter. Das
Hauptprinzip dieser Codierung besteht aus drei Schritten. Der erste
Schritt ist die Ermittlung der Spektralinformationen des
Eingangssignals mit Hilfe einer Voranalyse. Dann folgt die
Durchführung der FM-Analyse-Prozedur für die gewonnenen
FM-Parametersätze aus den geschätzten harmonischen
Spektrallinien. Der dritte Schritt ist die Quantisierung und
Codierung der geschätzten FM-Parameter. Bekanntlich haben
Musiksignale eine harmonische Struktur. Ihre Spektren zeichnen sich
durch diskrete Frequenzen aus, welche aus ganzen mehrfachen
Grundfrequenzen
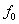 bestehen. Diese Informationen werden durch die Voranalyse in
harmonische Spektrallinienformate gepackt, als vereinfachtes
Signalmodell, dessen Parameter durch die FM-Analyse gewonnen werden
können. Die Voranalyse schätzt die harmonischen
Spektrallinien
bestehen. Diese Informationen werden durch die Voranalyse in
harmonische Spektrallinienformate gepackt, als vereinfachtes
Signalmodell, dessen Parameter durch die FM-Analyse gewonnen werden
können. Die Voranalyse schätzt die harmonischen
Spektrallinien
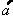 vom
gegebenen Eingangssignal. Sie beginnt mit der Berechnung der
relevanten Spektrallinien G(f) mit Hilfe
einer hochauflösenden Frequenzbewertungstechnik. Eine iterative
Suchprozedur mit einem erforderlichen Kriterium [13] wird zur
Identifizierung der Grundfrequenz
vom
gegebenen Eingangssignal. Sie beginnt mit der Berechnung der
relevanten Spektrallinien G(f) mit Hilfe
einer hochauflösenden Frequenzbewertungstechnik. Eine iterative
Suchprozedur mit einem erforderlichen Kriterium [13] wird zur
Identifizierung der Grundfrequenz
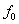 genutzt. Die harmonischen Muster der ganzen
Vielfachen von
genutzt. Die harmonischen Muster der ganzen
Vielfachen von
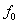 sollten
die meisten relevanten Spektrallinien verdecken
sollten
die meisten relevanten Spektrallinien verdecken

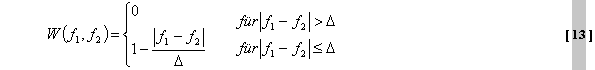
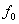 gewählt, so daß
gewählt, so daß
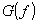 maximal wird.
Anschließend werden die einzelnen Teile zugewiesen. In dieser
Implementation ist die Grundfrequenz
maximal wird.
Anschließend werden die einzelnen Teile zugewiesen. In dieser
Implementation ist die Grundfrequenz
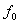 auf mindestes 50Hz begrenzt. Die Aufgabe der
FM-Analyse besteht in der Bewertung der FM-Parameter eines gegebenen
harmonischen Spektrums. Das Hauptprinzip unserer FM-Analyse ist die
Gewinnung von FM-Parametern durch Bewertung der eingehenden
Spektrallinien
auf mindestes 50Hz begrenzt. Die Aufgabe der
FM-Analyse besteht in der Bewertung der FM-Parameter eines gegebenen
harmonischen Spektrums. Das Hauptprinzip unserer FM-Analyse ist die
Gewinnung von FM-Parametern durch Bewertung der eingehenden
Spektrallinien
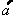 und
Minimierung des Fehlers. Die geschätzten Spektrallinien sind
synthetisch im Sinne von FM-Operatoren, welche in einer parallelen
Struktur kombiniert sind. Die FM-Parametersätze werden
numerisch optimiert, nacheinander für jeden FM-Operator. Eine
detailierte Beschreibung der Bestandteile der FM-Analyse folgt nun.
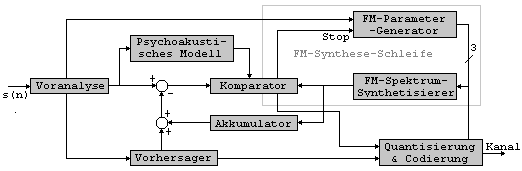
Das psychoakustische Modell berechnet eine maskierende Schwelle aus
einem gegeben Eingangsspektrum. Es wurde vereinfacht von einem
Modell hochqualitativer Transformations/Teilband-basierter
Audiocodierung übernommen. Die Effekte der Vor- und
Nachverdeckung werden in dieser Implementation nicht beachtet. Die
Berechnung der Maskierungsschwelle beginnt mit der Synthetisierung
eines Audiosignals aus den eingehenden Spektrallinien. Der
nächste Schritt ist die Einteilung (Mapping) der komplexen
Frequenzkomponenten eines synthetischen Audiosignals. Die
Maskierungsschwelle entscheidet, ob ein Spektrum, welches aus den
gewonnenen FM-Parametern synthetisiert wurde, das Eingangsspektrum
ausreichend annähert. Wird das Differenzspektrum maskiert, wird
die FM-Parameterbewertung gestoppt. Die FM-Syntheseschleife besteht
aus einem FM-Parameter-Generator und einem
FM-Spektrums-Synthetisierer. Die erste Einheit erzeugt iterativ die
FM Parameter in allen ihren möglichen Kombinationen
(FM-Operatoren). Basierend auf diesen FM-Parametern (Frequenzen,
Modulationsindex) synthetisiert die zweite Einheit das FM-Spektrum.
Die Bandbreite eines FM-Spektrums hängt vom Modulationsindex
ab, welcher im Bereich von 0 bis 15.5 (Schrittgroesse 0.5)
liegt. Dieser Komparator hat zwei Aufgaben. Die erste Aufgabe ist
die Bewertung eines jeden FM-Operators mit der optimalen
FM-Parameterkombination, welche iterativ durch den vorhergehenden
FM-Parameter-Generator erzeugt werden. Ist der optimale
Parametersatz erreicht, so wird die Optimierung der FM-Parameter
gestoppt und die aktuellen Parameter als optimaler FM-Parametersatz
gewählt. Die zweite Aufgabe ist die Bestimmung, ob die
Differenzspektrallinien unter der Maskierungsschwelle liegen. Wenn
ein oder mehrere Komponenten die Maskierungsschwelle
überschreiten, muß die erste Aufgabe des Komparators
wiederholt werden. Akkumulator und Vorhersager erzeugen das
Spektrum, aus dem später mit den neuen Spektrallinien das
Differenzspektrum erzeugt wird. Der Akkumulator sammelt FM-Spektren,
deren Parameter akzeptiert wurden und berechnet daraus immer wieder
“den” optimalen Parametersatz. Ein Vorhersager wird
benutzt, wenn die Voranalyse erkennt, daß der aktuelle Rahmen
die gleiche Grundfrequenz wie der letzte Rahmen hat. Dies führt
zu einer Vervielfachung des geschätzten Spektrums des letzten
Rahmens. Ein Koeffizient gibt diese Information an die
Codierungseinheit weiter. Die Anzahl der FM-Parametersätze,
welche übertragen werden muß, wird durch den Vorhersager
deutlich reduziert. Nach der Parameterbewertung für jeden
Rahmen folgt die Parametercodierung. Während die Amplitude und
die Grundfrequenz mit einer logarithmischen Skale quantisiert
werden, werden die anderen Parameter mit einer linearen Skale
quantisiert. Alle Parameter werden mit einer festen Wortlänge
codiert und übertragen (11).
und
Minimierung des Fehlers. Die geschätzten Spektrallinien sind
synthetisch im Sinne von FM-Operatoren, welche in einer parallelen
Struktur kombiniert sind. Die FM-Parametersätze werden
numerisch optimiert, nacheinander für jeden FM-Operator. Eine
detailierte Beschreibung der Bestandteile der FM-Analyse folgt nun.
Das psychoakustische Modell berechnet eine maskierende Schwelle aus
einem gegeben Eingangsspektrum. Es wurde vereinfacht von einem
Modell hochqualitativer Transformations/Teilband-basierter
Audiocodierung übernommen. Die Effekte der Vor- und
Nachverdeckung werden in dieser Implementation nicht beachtet. Die
Berechnung der Maskierungsschwelle beginnt mit der Synthetisierung
eines Audiosignals aus den eingehenden Spektrallinien. Der
nächste Schritt ist die Einteilung (Mapping) der komplexen
Frequenzkomponenten eines synthetischen Audiosignals. Die
Maskierungsschwelle entscheidet, ob ein Spektrum, welches aus den
gewonnenen FM-Parametern synthetisiert wurde, das Eingangsspektrum
ausreichend annähert. Wird das Differenzspektrum maskiert, wird
die FM-Parameterbewertung gestoppt. Die FM-Syntheseschleife besteht
aus einem FM-Parameter-Generator und einem
FM-Spektrums-Synthetisierer. Die erste Einheit erzeugt iterativ die
FM Parameter in allen ihren möglichen Kombinationen
(FM-Operatoren). Basierend auf diesen FM-Parametern (Frequenzen,
Modulationsindex) synthetisiert die zweite Einheit das FM-Spektrum.
Die Bandbreite eines FM-Spektrums hängt vom Modulationsindex
ab, welcher im Bereich von 0 bis 15.5 (Schrittgroesse 0.5)
liegt. Dieser Komparator hat zwei Aufgaben. Die erste Aufgabe ist
die Bewertung eines jeden FM-Operators mit der optimalen
FM-Parameterkombination, welche iterativ durch den vorhergehenden
FM-Parameter-Generator erzeugt werden. Ist der optimale
Parametersatz erreicht, so wird die Optimierung der FM-Parameter
gestoppt und die aktuellen Parameter als optimaler FM-Parametersatz
gewählt. Die zweite Aufgabe ist die Bestimmung, ob die
Differenzspektrallinien unter der Maskierungsschwelle liegen. Wenn
ein oder mehrere Komponenten die Maskierungsschwelle
überschreiten, muß die erste Aufgabe des Komparators
wiederholt werden. Akkumulator und Vorhersager erzeugen das
Spektrum, aus dem später mit den neuen Spektrallinien das
Differenzspektrum erzeugt wird. Der Akkumulator sammelt FM-Spektren,
deren Parameter akzeptiert wurden und berechnet daraus immer wieder
“den” optimalen Parametersatz. Ein Vorhersager wird
benutzt, wenn die Voranalyse erkennt, daß der aktuelle Rahmen
die gleiche Grundfrequenz wie der letzte Rahmen hat. Dies führt
zu einer Vervielfachung des geschätzten Spektrums des letzten
Rahmens. Ein Koeffizient gibt diese Information an die
Codierungseinheit weiter. Die Anzahl der FM-Parametersätze,
welche übertragen werden muß, wird durch den Vorhersager
deutlich reduziert. Nach der Parameterbewertung für jeden
Rahmen folgt die Parametercodierung. Während die Amplitude und
die Grundfrequenz mit einer logarithmischen Skale quantisiert
werden, werden die anderen Parameter mit einer linearen Skale
quantisiert. Alle Parameter werden mit einer festen Wortlänge
codiert und übertragen (11).







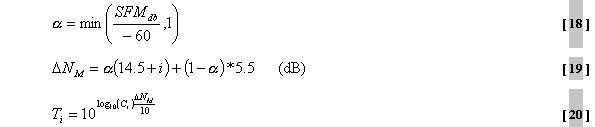
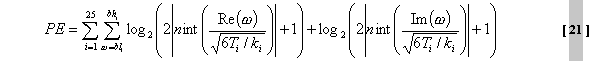
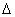 wird
die erlaubte Rauschenergie THR(k) an der
Maskierungsschwelle vom psychoakustischem Modell für jeden Koeffizienten
k vorhergesagt:
wird
die erlaubte Rauschenergie THR(k) an der
Maskierungsschwelle vom psychoakustischem Modell für jeden Koeffizienten
k vorhergesagt:
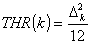
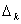 bezieht sich auf die
Quantisierungsschrittgroesse für die Koeffizienten
bezieht sich auf die
Quantisierungsschrittgroesse für die Koeffizienten 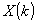
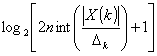
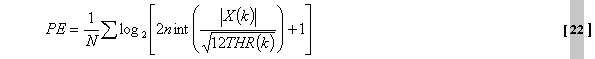




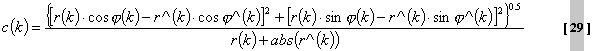


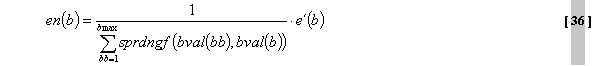

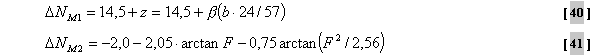



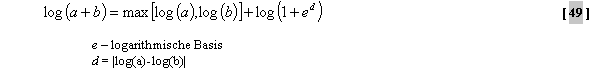


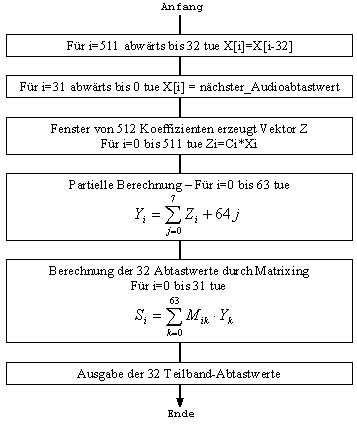
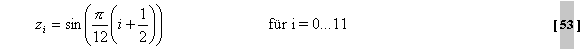
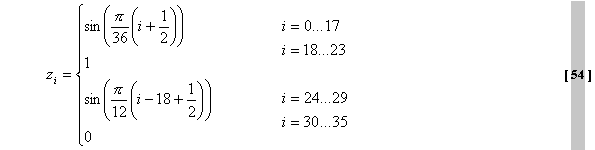
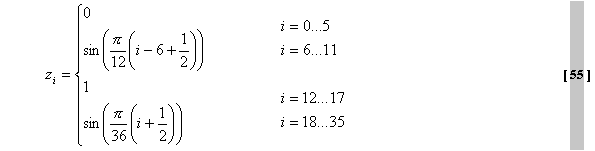
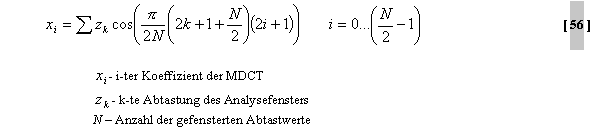
 das
Psychoakustische Mo
das
Psychoakustische Mo